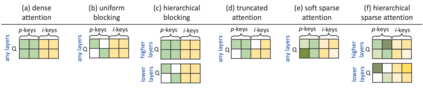
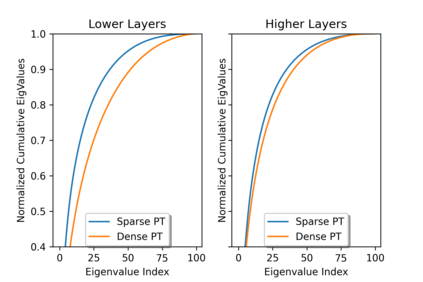
Current efficient fine-tuning methods (e.g., adapters, prefix-tuning, etc.) have optimized conditional text generation via training a small set of extra parameters of the neural language model, while freezing the rest for efficiency. While showing strong performance on some generation tasks, they don't generalize across all generation tasks. In this work, we show that prompt based conditional text generation can be improved with simple and efficient methods that simulate modeling the discourse structure of human written text. We introduce two key design choices: First we show that a higher-level discourse structure of human written text can be modelled with \textit{hierarchical blocking} on prefix parameters that enable spanning different parts of the input and output text and yield more coherent output generations. Second, we propose sparse prefix tuning by introducing \textit{attention sparsity} on the prefix parameters at different layers of the network and learn sparse transformations on the softmax-function, respectively. We find that sparse attention enables the prefix-tuning to better control of the input contents (salient facts) yielding more efficient tuning of the prefix-parameters. Experiments on a wide-variety of text generation tasks show that structured design of prefix parameters can achieve comparable results to fine-tuning all parameters while outperforming standard prefix-tuning on all generation tasks even in low-resource settings.
翻译:目前有效的微调方法(例如,适配器、前置调等)已经优化了有条件的文本生成,通过培训神经语言模型的一小部分额外参数,优化了有条件的文本生成,同时将其余参数冻结在效率上。在显示某些生成任务的强效性的同时,它们不会在所有生成任务中一概而论。在这项工作中,我们表明,以模拟人类书面文本的谈话结构模拟简单而高效的方法可以改进基于快速的有条件文本生成。我们引入了两种关键设计选择:首先,我们表明,在前置参数上,可以仿制更高层次的人类书面文本表达结构,以\textit{hitrachical clocktfrought为模型,从而能够跨越输入和输出文本的不同部分,产生更一致的一代产出。第二,我们建议通过在网络不同层次引入前置参数上引入 & textitleitut{ative screaility,并学习软模功能的微调。我们发现,低调的注意力使得前置式调整能够更好地控制输入内容(即使是低调的低度的设置)前置中,甚至更精确的设置的设置的参数,从而可以使所有生成前的创建前的系统能显示所有结构化前制成前制成前的系统前制成。