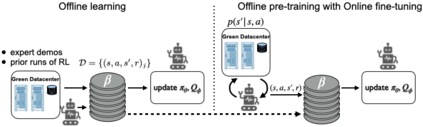
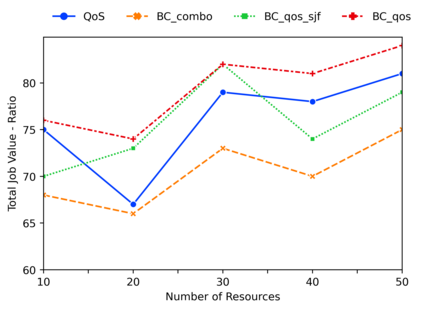
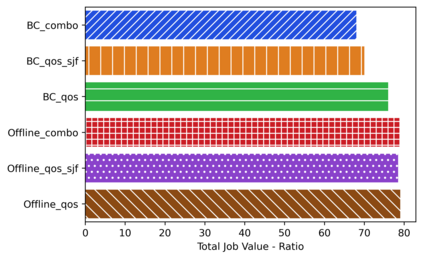
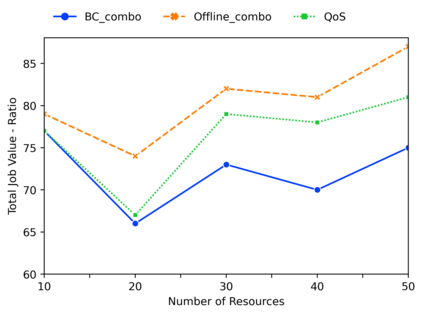
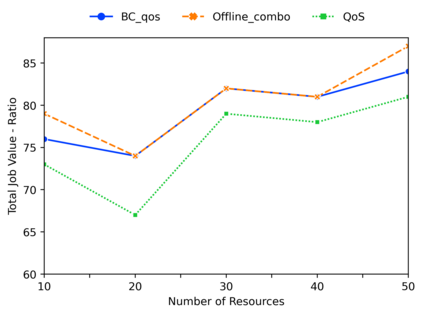
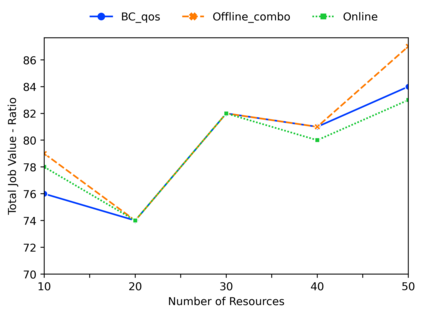
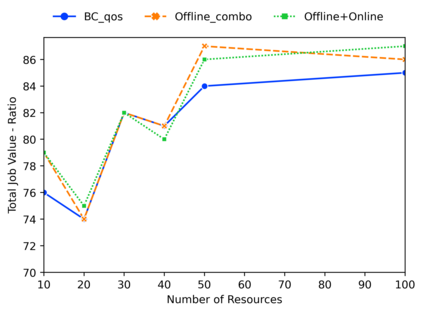
Deep reinforcement learning algorithms have succeeded in several challenging domains. Classic Online RL job schedulers can learn efficient scheduling strategies but often takes thousands of timesteps to explore the environment and adapt from a randomly initialized DNN policy. Existing RL schedulers overlook the importance of learning from historical data and improving upon custom heuristic policies. Offline reinforcement learning presents the prospect of policy optimization from pre-recorded datasets without online environment interaction. Following the recent success of data-driven learning, we explore two RL methods: 1) Behaviour Cloning and 2) Offline RL, which aim to learn policies from logged data without interacting with the environment. These methods address the challenges concerning the cost of data collection and safety, particularly pertinent to real-world applications of RL. Although the data-driven RL methods generate good results, we show that the performance is highly dependent on the quality of the historical datasets. Finally, we demonstrate that by effectively incorporating prior expert demonstrations to pre-train the agent, we short-circuit the random exploration phase to learn a reasonable policy with online training. We utilize Offline RL as a launchpad to learn effective scheduling policies from prior experience collected using Oracle or heuristic policies. Such a framework is effective for pre-training from historical datasets and well suited to continuous improvement with online data collection.
翻译:深层强化学习算法在一些具有挑战性的领域取得了成功。 典型的在线 RL 工作调度员可以学习高效的时间安排战略,但往往需要数千个时间步骤来探索环境,并随机地根据DNN政策进行调整。 现有的 RL 调度员忽略了从历史数据中学习和改进定制的疲劳政策的重要性。 离线强化学习展示了在没有在线环境互动的情况下从预录数据集中进行政策优化的前景。 在数据驱动学习最近成功之后,我们探索了两种RL 方法:(1) 行为克隆和(2) 脱线 RL,其目的是从登录的数据中学习政策,而无需与环境互动。 这些方法解决了数据收集和安全成本方面的挑战,特别是与RL 实际应用相关的。 尽管以数据驱动的 RL 方法产生了良好的结果,但我们表明,在收集历史数据集之前,业绩高度取决于历史数据集的质量。 最后,我们证明,通过将先前的专家演示有效地纳入对代理进行预编程,我们缩短了随机探索阶段,以通过在线培训学习合理的政策。 我们利用离线 RL 作为启动平台,以便学习有效的在线培训, 学习有效的在线列表政策, 学习有效的在线升级, 以在收集之前, 从持续更新历史数据, 和持续更新之前学习有效的在线培训中学习有效的在线培训。