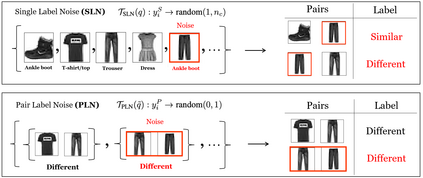
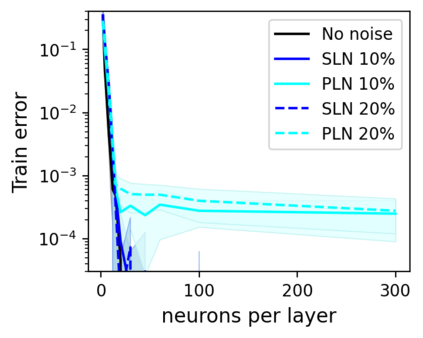
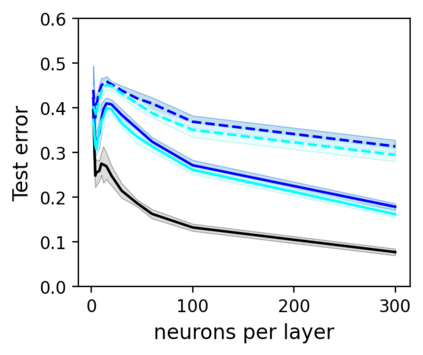
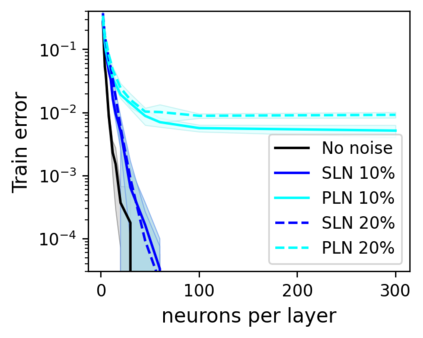
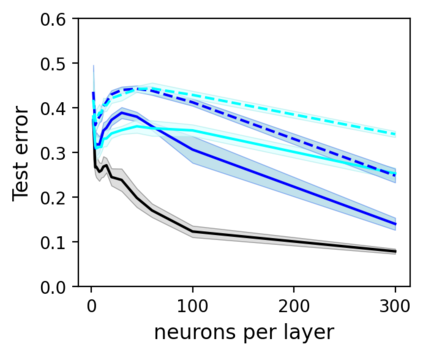
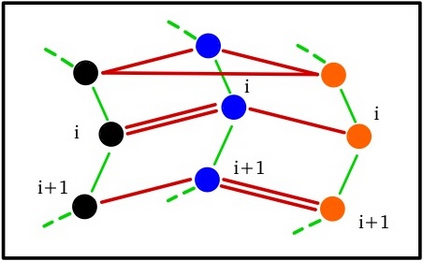
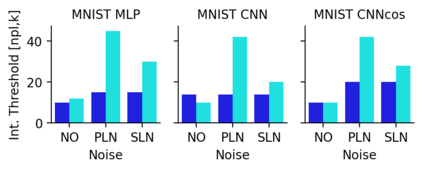
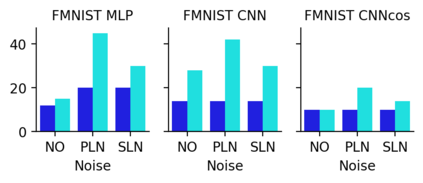
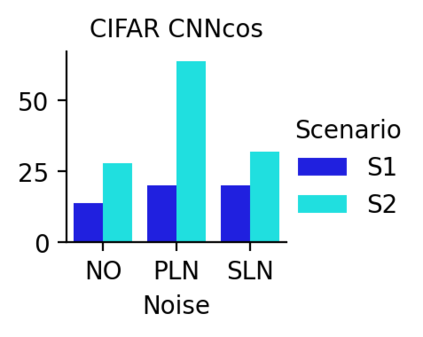
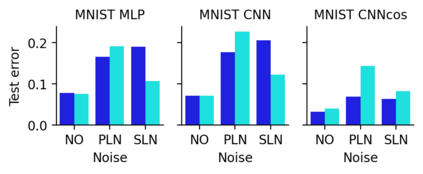
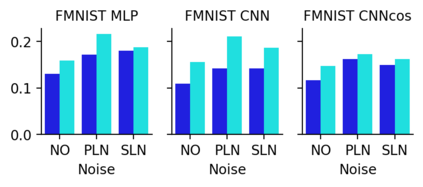
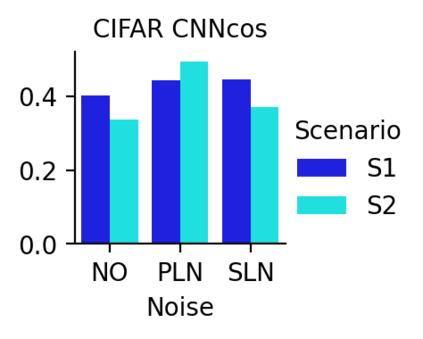
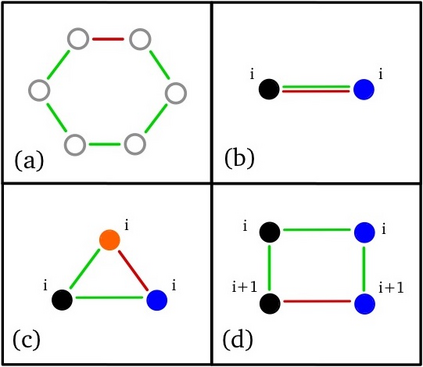
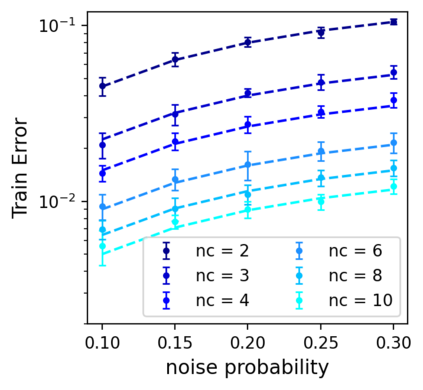
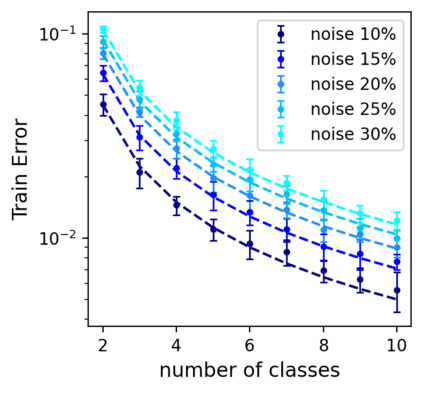
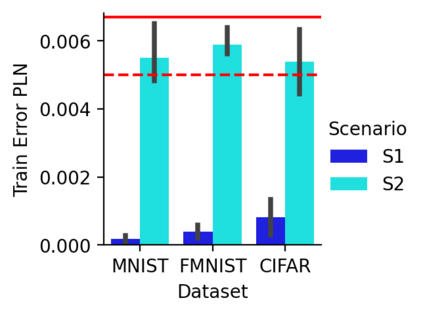
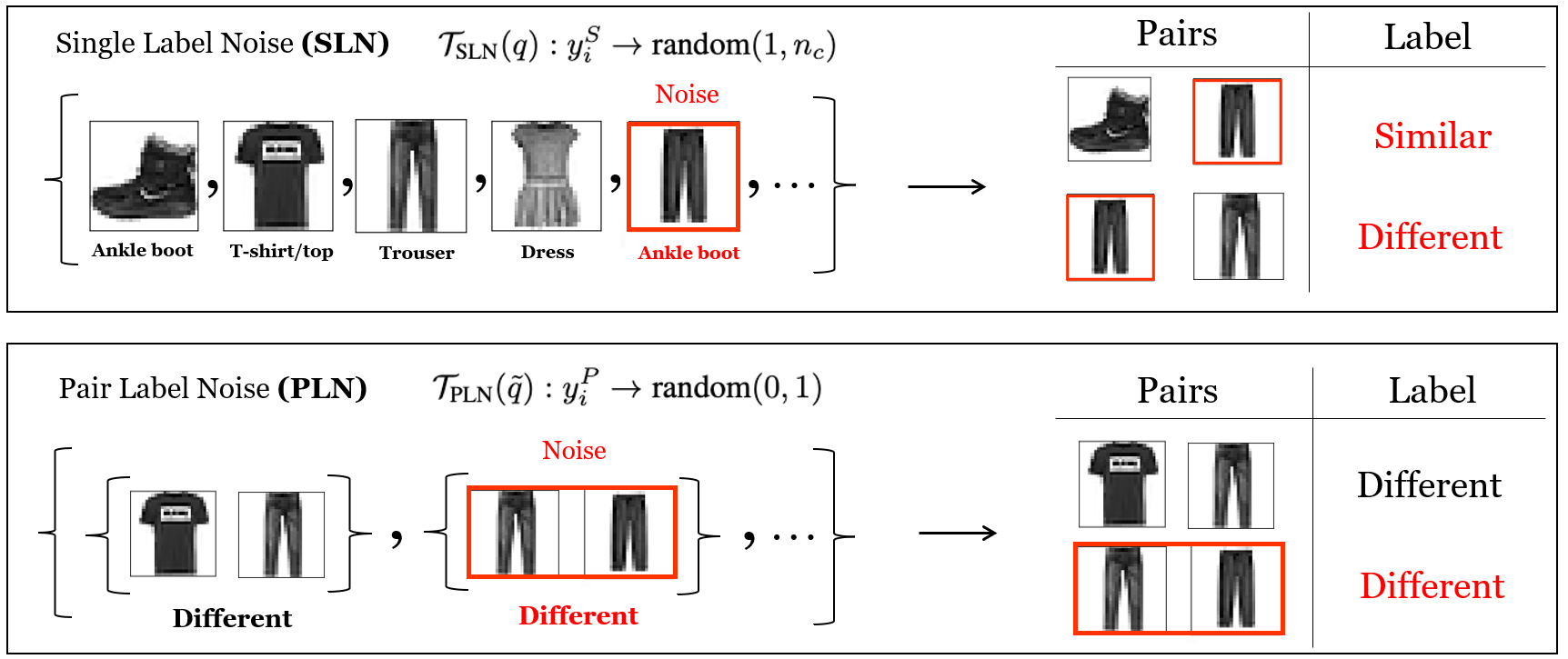
This work uncovers an interplay among data density, noise, and the generalization ability in similarity learning. We consider Siamese Neural Networks (SNNs), which are the basic form of contrastive learning, and explore two types of noise that can impact SNNs, Pair Label Noise (PLN) and Single Label Noise (SLN). Our investigation reveals that SNNs exhibit double descent behaviour regardless of the training setup and that it is further exacerbated by noise. We demonstrate that the density of data pairs is crucial for generalization. When SNNs are trained on sparse datasets with the same amount of PLN or SLN, they exhibit comparable generalization properties. However, when using dense datasets, PLN cases generalize worse than SLN ones in the overparametrized region, leading to a phenomenon we call Density-Induced Break of Similarity (DIBS). In this regime, PLN similarity violation becomes macroscopical, corrupting the dataset to the point where complete interpolation cannot be achieved, regardless of the number of model parameters. Our analysis also delves into the correspondence between online optimization and offline generalization in similarity learning. The results show that this equivalence fails in the presence of label noise in all the scenarios considered.
翻译:暂无翻译