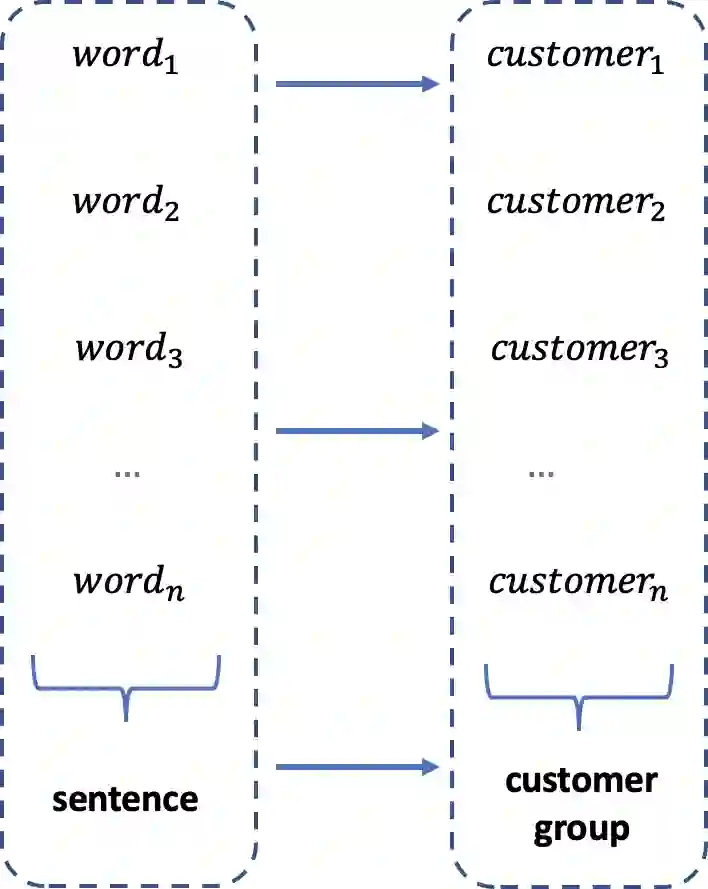
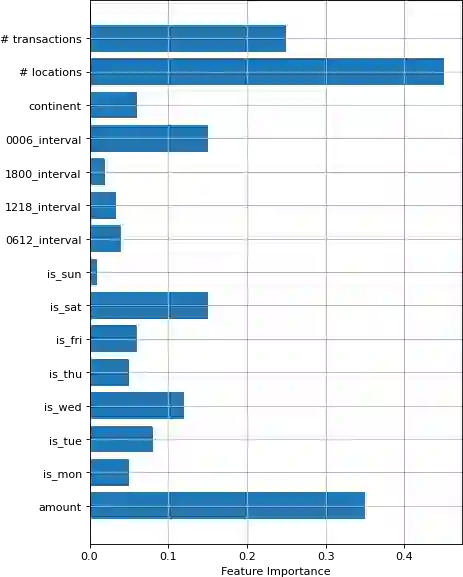
Today, machine learning is applied in almost any field. In machine learning, where there are numerous methods, classification is one of the most basic and crucial ones. Various problems can be solved by classification. The feature selection for model setup is extremely important, and producing new features via feature engineering also has a vital place in the success of the model. In our study, fraud detection classification models are built on a labeled and imbalanced dataset as a case-study. Although it is a natural language processing method, a customer space has been created with word embedding, which has been used in different areas, especially for recommender systems. The customer vectors in the created space are fed to the classification model as a feature. Moreover, to increase the number of positive labels, rows with similar characteristics are re-labeled as positive by using customer similarity determined by embedding. The model in which embedding methods are included in the classification, which provides a better representation of customers, has been compared with other models. Considering the results, it is observed that the customer embedding method had a positive effect on the success of the classification models.
翻译:今天,机器学习几乎在任何领域都应用。在机器学习中,有许多方法,分类是最基本的和最关键的方法之一。各种问题可以通过分类来解决。模型设置的特征选择极为重要,通过特征工程产生新的特征对于模型的成功也具有关键的位置。在我们的研究中,欺诈检测分类模型建立在标签和不平衡的数据集上,作为案例研究。虽然这是一种自然语言处理方法,但已经用文字嵌入创造了一个客户空间,这些词嵌入已经在不同领域使用,特别是用于推荐者系统。在创建的空间中的客户矢量被输入到分类模型中,作为特性。此外,为了增加正面标签的数量,使用嵌入确定的客户相似性,具有类似特征的行被重新标为正面的行。将嵌入方法纳入分类的模型,提供了更好的客户代表性,与其他模型进行了比较。考虑到结果,发现客户嵌入方法对分类模型的成功产生了积极影响。