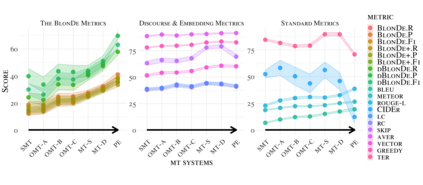
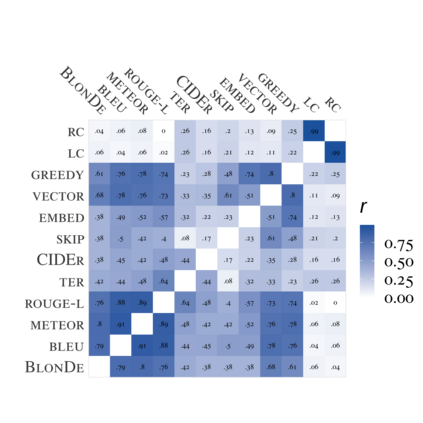
Standard automatic metrics, e.g. BLEU, are not reliable for document-level MT evaluation. They can neither distinguish document-level improvements in translation quality from sentence-level ones, nor identify the discourse phenomena that cause context-agnostic translations. This paper introduces a novel automatic metric BlonDe to widen the scope of automatic MT evaluation from sentence to document level. BlonDe takes discourse coherence into consideration by categorizing discourse-related spans and calculating the similarity-based F1 measure of categorized spans. We conduct extensive comparisons on a newly constructed dataset BWB. The experimental results show that BlonDe possesses better selectivity and interpretability at the document-level, and is more sensitive to document-level nuances. In a large-scale human study, BlonDe also achieves significantly higher Pearson's r correlation with human judgments compared to previous metrics.
翻译:标准自动衡量标准,如BLEU,对于文件一级的MT评估来说是不可靠的,它们既不能区分翻译质量的文件水平改进与判决水平的改善,也不能辨别导致背景不可知翻译的谈话现象。本文介绍了一个新的自动衡量标准Blonde,以扩大自动MT评价的范围,从判决到文件水平。Blonde通过对讨论的跨度进行分类和计算分类的基于相似的F1尺度来考虑讨论的一致性。我们对新建的数据集BWB进行广泛的比较。实验结果显示,Blonde在文件水平上具有更好的选择性和可解释性,而且对文件水平的细微之处更为敏感。在一项大规模的人类研究中,Blonde还实现了与人类判断比以往的尺度要高得多的皮尔逊与人类判断的相关性。