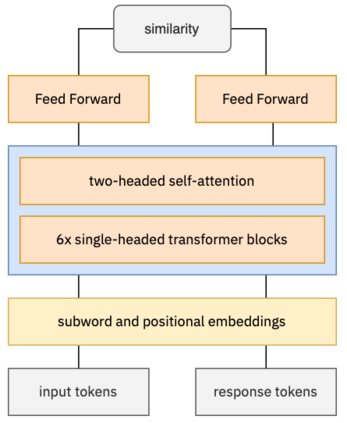
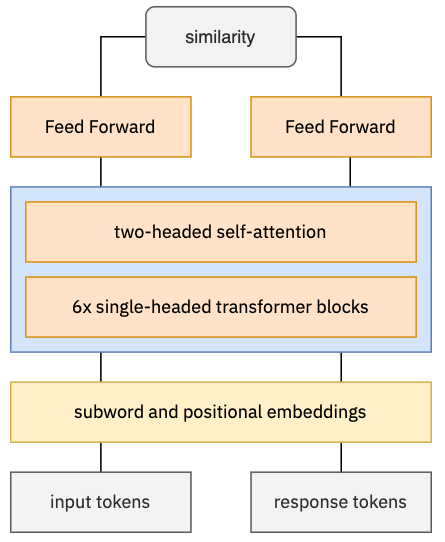
Knowledgeable FAQ chatbots are a valuable resource to any organization. While powerful and efficient retrieval-based models exist for English, it is rarely the case for other languages for which the same amount of training data is not available. In this paper, we propose a novel pre-training procedure to adapt ConveRT, an English conversational retriever model, to other languages with less training data available. We apply it for the first time to the task of Dutch FAQ answering related to the COVID-19 vaccine. We show it performs better than an open-source alternative in both a low-data regime and a high-data regime.
翻译:对于任何组织来说,可以学习的FAQ聊天机都是宝贵的资源。 虽然英语有强大而高效的检索模型,但对于其他语言来说却很少如此,因为没有同样数量的培训数据。在本文中,我们提出一个新的培训前程序,将英语对话检索器模型ConveRT改编为培训数据较少的其他语言。我们第一次将它应用到荷兰的回答与COVID-19疫苗有关的任务中。我们在低数据制度和高数据制度中显示它的表现优于开放源的替代方法。