KBQA: 基于开放域知识库上的QA系统 | 每周一起读

本期论文
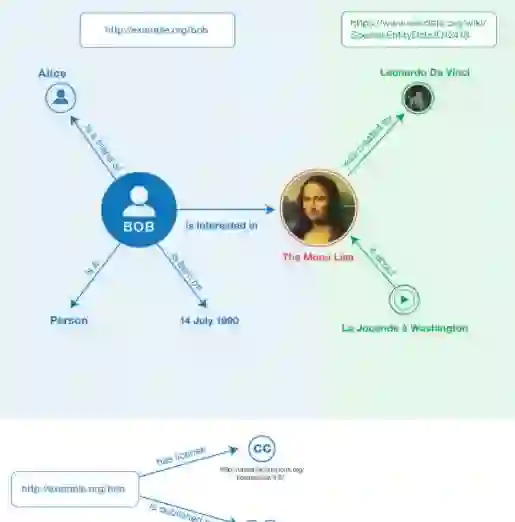
KBQA: Learning Question Answering over QA Corpora and Knowledge Bases
本文在开放域知识库基础上构建 QA 系统。针对目前 QA 系统常用的规则只能理解规则内固定问题模式,而基于关键字或基于同义词的方法不能完全理解问题,提出一种基于亿级知识库和百万级 QA 语料库的模板。结合问题中实体,知识库谓词,问题的表达形式等,从而得到问题的语义,并与知识库中RDF三元组映射。
论文链接:
http://www.vldb.org/pvldb/vol10/p565-cui.pdf
阅读笔记精选
❶
LeoZhao
本文专注于解决 BFQ。利用问题模板 – 谓词 predicate 的对应关系。问题 → 提取实体 → 问题抽象成模板 → 模板与谓词的对应关系 → 答案。
本质上是解决问题理解 question answer 这个问题。 一般的问题理解解决过程有:
1. 关键词提取, → 本文中是实体提取,这里主要是为了抽象成模板 conceptualization question keywords extraction (or question labeling), identifying the focus of the question.
2. 问题分类, → 本文使用的是基于 KB 的实体分类的抽象成模板的方法 question classification, determining the category or semantic type of the question.
3. 问题扩展 → question extension, generating similar questions to extract all possible answers.
这个算法的关键在于:
1. 训练的问题的模板丰度。这个可以考虑根据语料生成问题?查阅相关论文时, 看到一篇论文:通过语料生成问题, Generating Factoid Questions With Recurrent Neural Networks: The 30M Factoid Question-Answer Corpus。这部分还需要细细看。
2. 知识库的谓词丰度。 这个针对工程中相对垂直的领域,比较好解决。
3. NER识别中的别称问题等,即问题实体与知识库实体不对应的情况。这个本文不涉及。
4. 如何解决抽象过程中, 一个实体对应的多个 category 问题。 文中采用的是《Short Text Conceptualization using a Probabilistic Knowledgebase》另外采用的解法,LDA 系列的统计方法《Context-Dependent Conceptualization》基于其他 KB,如WordNet, Freebase, Wikipedia。
5. 文中训练时候的 UIUC taxonomy 是谓词与模板配对精度的关键。关于 Question Classification 有一篇《高考历史题的提问分类》:
http://ieeexplore.ieee.org/abstract/document/7875951/
与之前读过的 R-net(reading comprehension,从文章中找出问题的答案)属于不同的问题。 后者是从文章中找答案,前者是从知识库中找答案。R-NET 主要建立的是问题形式 –(question-passage matching)- 答案形式 –(self-matching)- 答案这样的关系。 本文建立是谓词-问题形式的关系。
❷
karis
本文主要提出了一种基于概率图的 QA 映射方法,而传统的基于规则、关键词、同义词的方法各有其局限。
本文对 QA 任务定义为求解 P(q,e,t,p,v) 的联合概率,其中 5 个变量分别代表问题、问题中的实体、问题模板、谓词和答案。这 5 个变量之间存在依赖关系,所以联合概率的求解转化为若干条件概率的参数估计或计算,包括 p(e|q)、p(t|e,q)、p(p|t) 和 p(v|e,p)。这 5 个参数的学习和计算利用了 RDF 知识库及 QA 语料库。
本文也给出了这种知识库问答的系统架构,其离线流程的目标都是计算 P(q,e,t,p,v) 相应的参数。线上流程主要包含两个方面:question parsing 计算 p(e|q) 和 p(t|e,q);inference 计算 p(p|t) 的过程;最后根据 RDF 知识库计算 p(v|e,p)。
❸
waitting
论文线下构建问题的表征模板,这些模板从语义理解角度出发,融合了查询的各种意图,以此为背景支撑,旨在能够更好地理解线上用户提出的问题。过程中考虑了抽取的模板、问题中包含的实体、问题的答案、知识库中的谓词等它们之间的分布关系。针对复杂问题,可以将其分解成几个子问题来解决。 谓词扩展这个思路觉得很不错。
❹
lizhili
作者设计了一种新的问题表示方法:模板。为了回答问题,需要将问题表示成为模板形式来抓住问题的语义和意图。之后和知识库中的 RDF(s,p,o) 进行映射。为了得到问题表示,将问题和已经存在的模板进行映射。KBQA 具体实现是通过 P(e|q) 得到问题中实体,通过 P(t|q,e) 得到问题模板,之后通过 P(v|e,p) 得到回答,其中预测 p 与模板 t 相关,是在 offline 处理得到的。
❺
veraLzz
本文首先解决 BFQ 问题,即关于某个实体的特性的询问。对于复杂问题,可以将其分解成多个 BFQ 问题,然后推理求解。对于 BRF 问题,1)先利用语料把问题匹配到模板,这里通过识别实体和他的值,将实体值转换成他的概念词。得到比较多模板。2)将多个模板对应到知识库中的某个 predicate,即三元组中的关系或动词。这一步是通过一个假设实现,假如一个模板的多个实例都对应于同一个 predicate,那么这个模板也匹配到这个 predicate。3)最后利用概率推论方法找到 BFQ 的值。
❻
beryl
本文在开放域知识库基础上构建 QA 系统,几个亮点:1. 通过 templates 理解 question,2. 由问题和实体提取 template,3. 扩展了谓词,这个思路可以借鉴,4.把复杂问题分解为简单问题。
其中有 4 个概率分布:question->entity,question&entity->template,template->predicate,entity&predicate->value,概率分布的设计值得借鉴。
Q&A 精选
❶
zhkun
In addition to BFQ and its variants, we can answer a complex factoid question such as when was Barack Obama’s wife born? This canbe answered by combining the answers of two BFQs: who’s Barack Obama’s wife? (Michelle Obama) and when was Michelle Obama born? (1964).
目前这种将一个问题分解为几个简单的子问题的方法感觉变得越来越流行了。
Charnugagoo: 前几年流行的 Semantic Parsing,在 grounded 之后目标就是解决这种复杂的问题。例如:
http://sivareddy.in/papers/reddy2016transforming.pdf
这个方向最终因为不能解决稍微复杂的提问,同时也有很多 bug,导致进展不好。但是我觉得,实用上讲,这样 2,3 个简单子问题合并的问题,这个方法解决挺好的。至少,grounded 之前的部分,是 robust 的。
❷
Herbert002
QA over a knowledge base has a long history. In recent years, large scale knowledge bases become available, including Google’s Knowledge Graph, Freebase [3], YAGO2 [16], etc., greatly increase the importance and the commercial value of a QA system.
KBQA 这几年好火,原因应该很多:大厂的示范;机器学习技术在 NLP 的应用逐渐深入;人工智能行业事件的推动。但需要解决的问题还是很多。
yuhe: 看起来,这个研究领域也像是找到了一个很实用的应用场景,如各大搜索引擎在某些搜索词下的图谱展示,前言也说了,这样给出的信息更简洁,更精准,所以节省了用户停留时间。应该是在信息展示的全面性和冗余性之间的一个比较好的折衷。
❸
Herbert002
Rule based [23].
看了参考文献【23】,感觉基于规则(rule)和基于模板(template)的方法非常相似,它们的差别在哪里呢?
ngly: 感觉模板也是规则的一种,可以理解为 question-template-predicate 的对应,而规则直接为 question-predicate。
rqyang: 文中提到 rule based 主要是 manually constructed,而模板是通过 conceptualization 再替换实体生成的,或许这里的点在于使用了外部的通用规则,而对领域相关的知识依赖较少吧。
❹
lc222
Furthermore, we expand predicates in RDF knowledge base, which boosts the coverage of knowledge base by 57 times.
看了后面的示意图之后,还是不太懂 RDF,有没有比较简单直观的解释?
cuixiankun: 就是一种知识图谱,说实话,我也觉得把对话和图谱结合着搞才有应用价值,我也一直在关注对话生成和知识图谱相关的研究,目前还没有太好的突破口。有类似感兴趣的同学希望能一块儿讨论下。
cuixiankun: 我觉得未来工作可能是要消除问答与图谱之间在表示上的差异。要么调整问答的表示方式,去适应在图谱上的匹配,也是这篇论文做的工作;要么构建可以适配上下文的图谱向量表示,去完成自然语言上的计算,例如知识图谱表示学习的相关工作。
cuixiankun: 可以简单看做是对各种事实的一组陈述(statement,表现为形式)的集合。statement,以三元组 subject, predict, object 的形式来表示。
❺
ghandzhipeng
In the QA corpora we use, we find 27M question templates over 2782 question intents.
Yahoo! Answer 中总共有 41M Q-A pairs,这里就抽出了 27M,是不是说这些模板共性很少?那么新问题来的话适应性怎么样?
zhkun: 这种抽模版的方式感觉不够灵活啊,还是通过依靠规则的方式去表示。
charnugagoo: 是否也有可能抽取的模板通用性不足,导致一些应该是同一模板的问题,抽成多个模板。
lizhili: 对于某一个问题也有可能多个意图,那是否会抽出多个模板?
❻
zhkun
Learning templates that map to a complex knowledge base structure employs a similar process.
这点感觉有点意思,寻找一个问题的答案时通过寻找一个路径,这个感觉可以用在对模型进行解释上,在一定程度上提高了模型的可解释性。
charnugagoo: 这个 idea 好,但是感觉不应该用 template 来做。我们可否,先 label 出所有的 noun phrases: 1. 能 map 到 entity 的 np 可以从 db 里抽取;2. 无法 map 到 db 里的,其实就是子问题。
论文共读报名方式
点击「阅读原文」提交内测申请,我们将在 48 小时内完成审核并和您取得联系。
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


点击 | 阅读原文 | 进行报名