搜狗开源机器阅读理解工具箱
【导读】机器阅读理解,是自然语言处理领域最具挑战的任务之一。每一个在阅读理解领域有突破的模型,都能够引领NLP发展一段时间。奈何,随着NLP的发展,阅读理解模型越来越复杂,小编常常看着眼花缭乱的模型结构图,望而却步。还好,搜狗在近期开源了其团队的机器阅读理解工具箱,工具向内实现了多种阅读理解的算法和模型,甚至有的模型的结果比模型作者训得都好,小编整理报道,希望对做阅读理解的同学有帮助。
Github地址:
https://github.com/sogou/SMRCToolkit
作者:
sougou
【工具箱结构】
工具箱内的工具,主要分为四个部分:数据集阅读器、数据处理、模型构建以及模型训练:
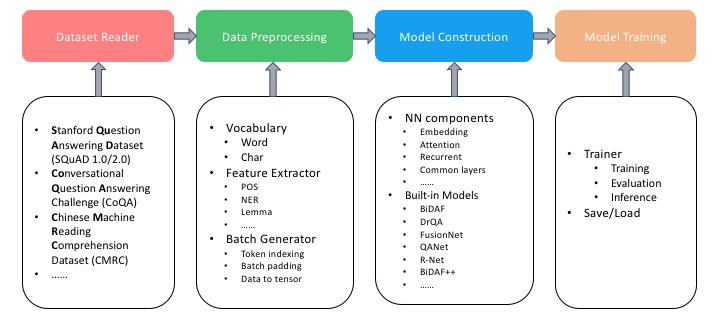
工具箱的文件夹结构如下:
datavocabulary.py: 字典构建
batch_generator.py: 将单词和标签映射到索引上,padding变长的特征,将所有特性转换为张量,然后对它们进行批处理
dataset_readersquad.py: SQuAD 1.0数据集的读取器
squadv2.py : SQuAD 2.0数据集的读取器
coqa.py : CoQA数据集的读取器
cmrc.py : CMRC数据集的读取器
examples用于运行不同模型的示例,需指定数据路径
model基类和模型的子类,其中任何模型都应该继承基类
内置模型,包括:BiDAF, DrQA, FusionNet等
nnsimilarity_function.py: 相似度计算函数
attention.py: 注意力方法,包括单注意力,双重注意力,三重注意力
ops: 常规操作库
recurrent: LSTM 和 GRU的一些封装
layers: 常用神经网络层
utilstokenizer.py: tokenizer,可用于英文和中文
feature_extractor: 语法特征提取器,提取如POS等
librariesBERT等外部模型,放在这里
【实现算法与性能】
F1/EM score on SQuAD 1.0 dev set
| Model | toolkit implementation | original paper |
|---|---|---|
| BiDAF | 77.3/67.7 | 77.3/67.7 |
| BiDAF+ELMo | 81.0/72.1 | - |
| IARNN-Word | 73.9/65.2 | - |
| IARNN-hidden | 72.2/64.3 | - |
| DrQA | 78.9/69.4 | 78.8/69.5 |
| DrQA+ELMO | 83.1/74.4 | - |
| R-Net | 79.3/70.8 | 79.5/71.1 |
| BiDAF++ | 78.6/69.2 | -/- |
| FusionNet | 81.0/72.0 | 82.5/74.1 |
| QANet | 80.8/71.8 | 82.7/73.6 |
| BERT-Base | 88.3/80.6 | 88.5/80.8 |
F1/EM score on SQuAD 2.0 dev set
| Model | toolkit implementation | original paper |
|---|---|---|
| BiDAF | 62.7/59.7 | 62.6/59.8 |
| BiDAF++ | 64.3/61.8 | 64.8/61.9 |
| BiDAF++ + ELMo | 67.6/64.8 | 67.6/65.1 |
| BERT-Base | 75.9/73.0 | 75.1/72.0 |
F1 score on CoQA dev set
| Model | toolkit implementation | original paper |
|---|---|---|
| BiDAF++ | 71.7 | 69.2 |
| BiDAF++ + ELMo | 74.5 | 69.2 |
| BERT-Base | 78.6 | - |
| BERT-Base+Answer Verification | 79.5 | - |
【安装方法】
你只需要将该代码库拉下来,然后pip install 即可:
$ git clone https://github.com/sogou/SMRCToolkit.git
$ cd SMRCToolkit
$ pip install [-e] .
快下下来试试吧。
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!540+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程




