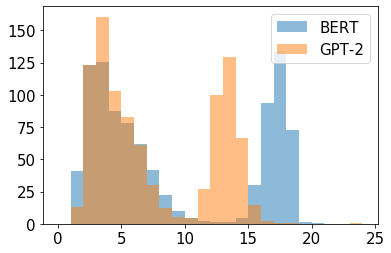
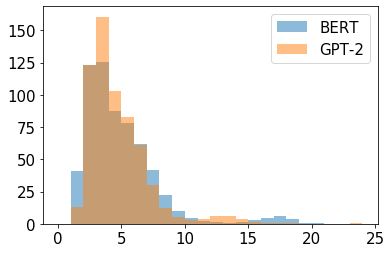
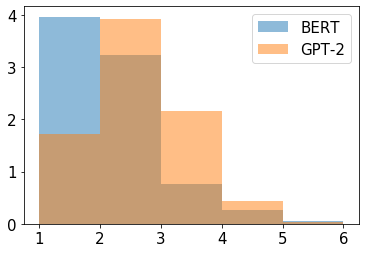
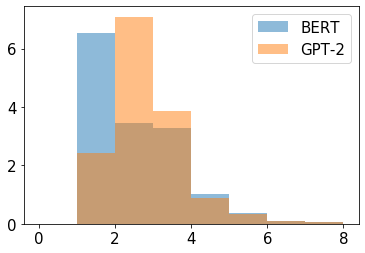
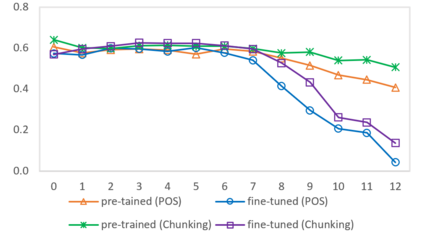
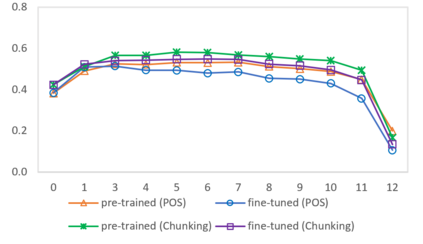
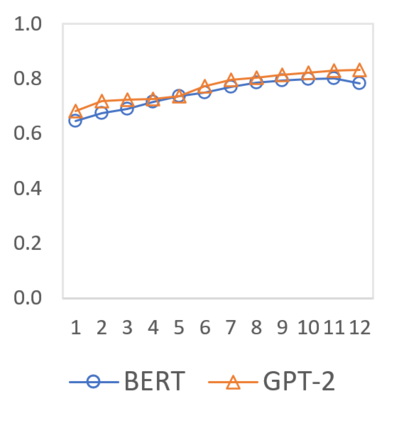
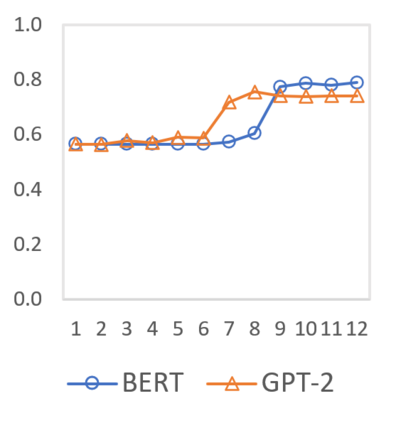
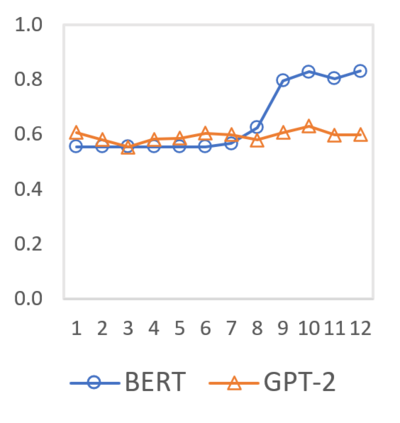
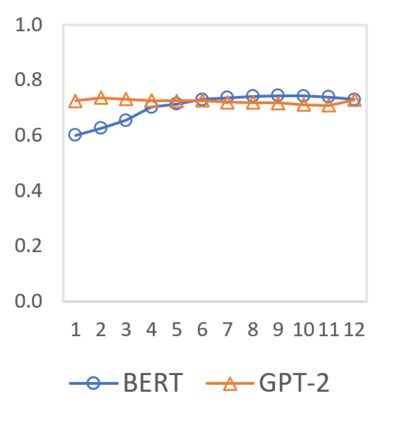
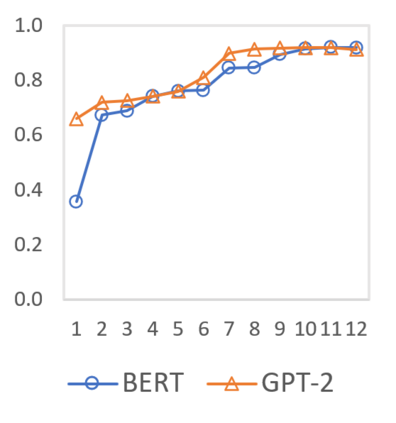
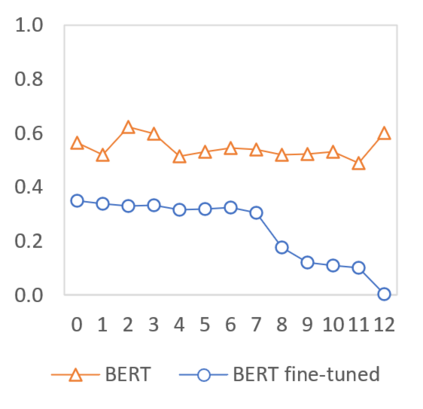
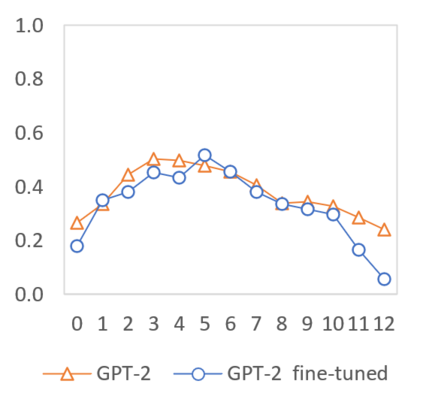
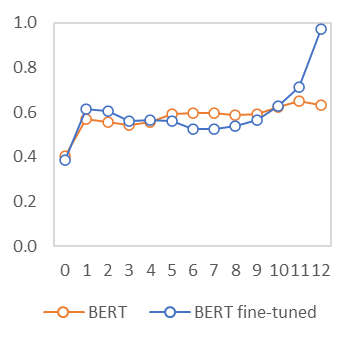
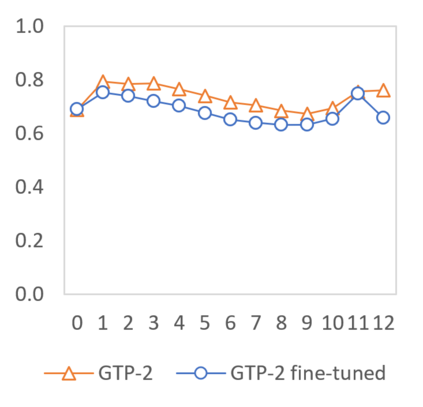
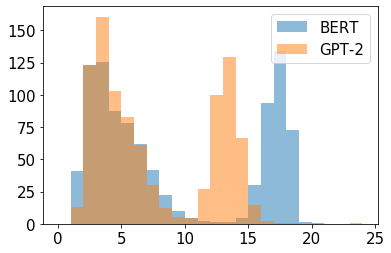
In this paper we shed light on the impact of fine-tuning over social media data in the internal representations of neural language models. We focus on bot detection in Twitter, a key task to mitigate and counteract the automatic spreading of disinformation and bias in social media. We investigate the use of pre-trained language models to tackle the detection of tweets generated by a bot or a human account based exclusively on its content. Unlike the general trend in benchmarks like GLUE, where BERT generally outperforms generative transformers like GPT and GPT-2 for most classification tasks on regular text, we observe that fine-tuning generative transformers on a bot detection task produces higher accuracies. We analyze the architectural components of each transformer and study the effect of fine-tuning on their hidden states and output representations. Among our findings, we show that part of the syntactical information and distributional properties captured by BERT during pre-training is lost upon fine-tuning while the generative pre-training approach manage to preserve these properties.
翻译:在本文中,我们阐述了在神经语言模型的内部表述中微调社会媒体数据的影响。我们注重在Twitter上检测机器人,这是减轻和抵制在社交媒体中自动传播虚假信息和偏见的关键任务。我们调查使用预先培训的语言模型,以解决检测由机器人或人类账户产生的完全基于其内容的推文的问题。不同于GLUE等基准的一般趋势,即BERT在常规文本的大多数分类任务中通常优于GPT和GPT-2等基因变异器。我们观察到,微调机器人检测任务上的基因变异器会产生更高的精度。我们分析了每个变异器的建筑构件,并研究了微调其隐藏状态和输出表现的效果。我们发现,在我们的研究结果中,BERT在预培训期间收集的部分合成信息和分布属性在微调后丢失,而基因变异器前方法设法保护这些特性。