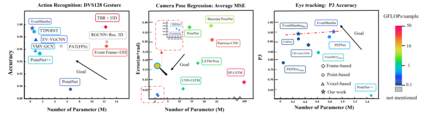
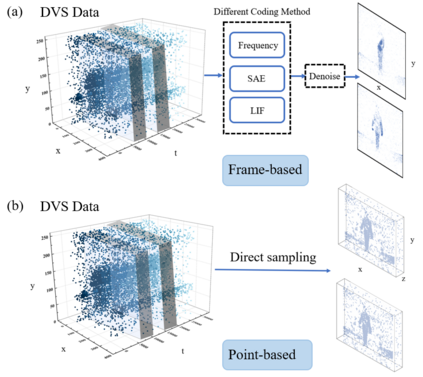
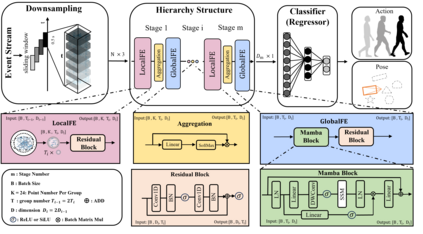
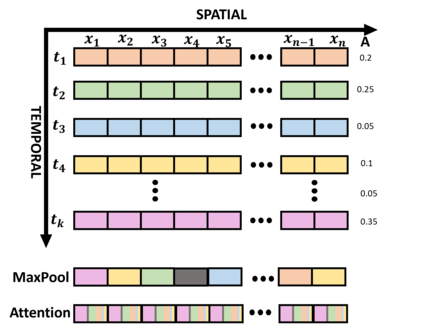
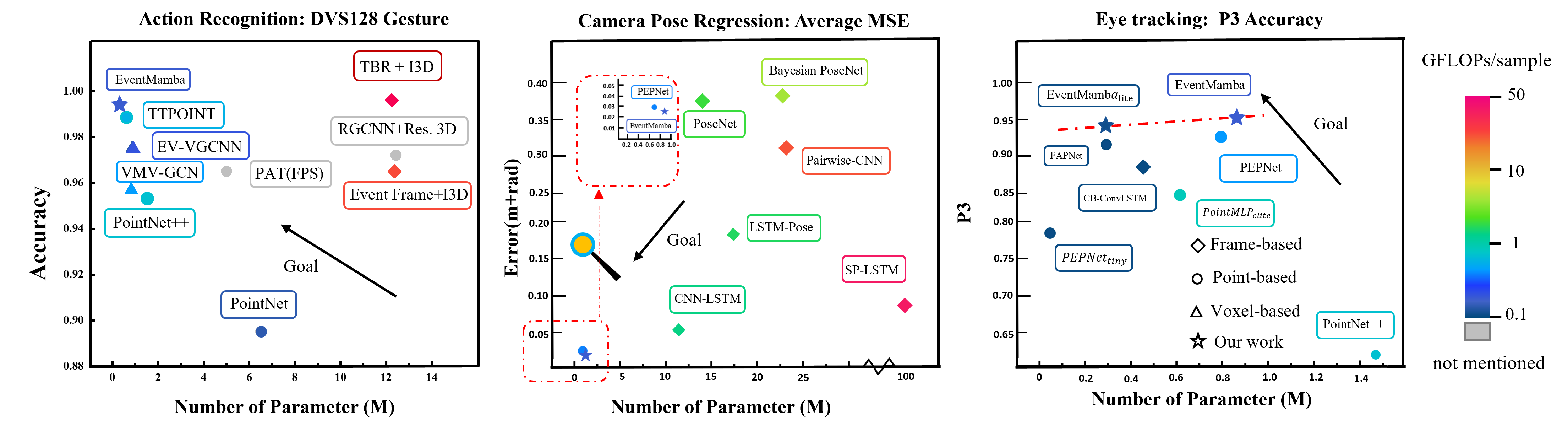
Event cameras draw inspiration from biological systems, boasting low latency and high dynamic range while consuming minimal power. The most current approach to processing Event Cloud often involves converting it into frame-based representations, which neglects the sparsity of events, loses fine-grained temporal information, and increases the computational burden. In contrast, Point Cloud is a popular representation for processing 3-dimensional data and serves as an alternative method to exploit local and global spatial features. Nevertheless, previous point-based methods show an unsatisfactory performance compared to the frame-based method in dealing with spatio-temporal event streams. In order to bridge the gap, we propose EventMamba, an efficient and effective framework based on Point Cloud representation by rethinking the distinction between Event Cloud and Point Cloud, emphasizing vital temporal information. The Event Cloud is subsequently fed into a hierarchical structure with staged modules to process both implicit and explicit temporal features. Specifically, we redesign the global extractor to enhance explicit temporal extraction among a long sequence of events with temporal aggregation and State Space Model (SSM) based Mamba. Our model consumes minimal computational resources in the experiments and still exhibits SOTA point-based performance on six different scales of action recognition datasets. It even outperformed all frame-based methods on both Camera Pose Relocalization (CPR) and eye-tracking regression tasks. Our code is available at: https://github.com/rhwxmx/EventMamba.
翻译:暂无翻译