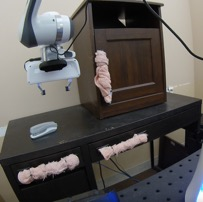
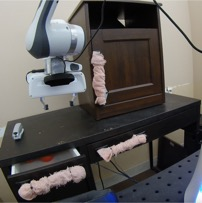
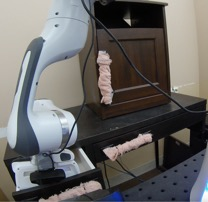
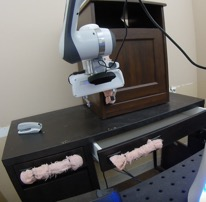
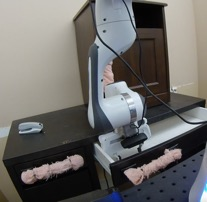
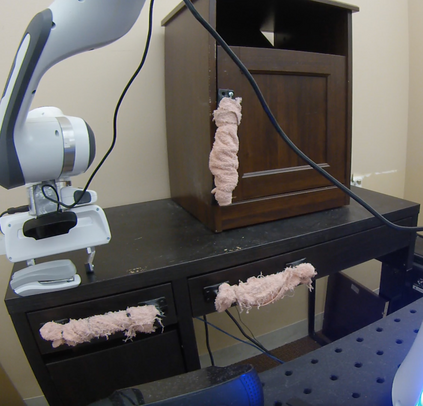
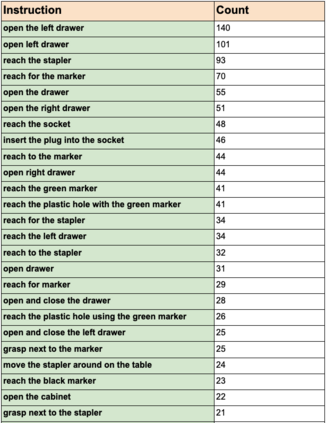
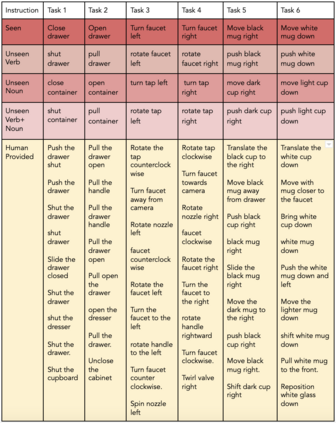
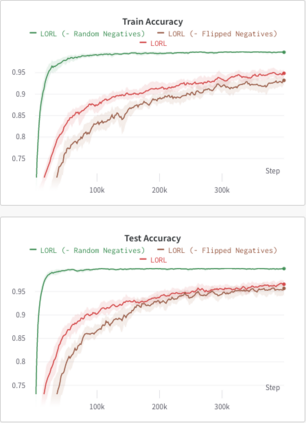
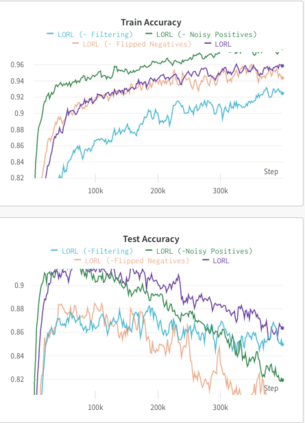
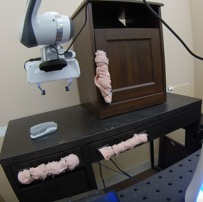
We study the problem of learning a range of vision-based manipulation tasks from a large offline dataset of robot interaction. In order to accomplish this, humans need easy and effective ways of specifying tasks to the robot. Goal images are one popular form of task specification, as they are already grounded in the robot's observation space. However, goal images also have a number of drawbacks: they are inconvenient for humans to provide, they can over-specify the desired behavior leading to a sparse reward signal, or under-specify task information in the case of non-goal reaching tasks. Natural language provides a convenient and flexible alternative for task specification, but comes with the challenge of grounding language in the robot's observation space. To scalably learn this grounding we propose to leverage offline robot datasets (including highly sub-optimal, autonomously collected data) with crowd-sourced natural language labels. With this data, we learn a simple classifier which predicts if a change in state completes a language instruction. This provides a language-conditioned reward function that can then be used for offline multi-task RL. In our experiments, we find that on language-conditioned manipulation tasks our approach outperforms both goal-image specifications and language conditioned imitation techniques by more than 25%, and is able to perform visuomotor tasks from natural language, such as "open the right drawer" and "move the stapler", on a Franka Emika Panda robot.
翻译:我们研究从机器人互动的大型离线数据集中学习一系列基于视觉的操纵任务的问题。 为了实现这一点, 人类需要简单、 有效的方式为机器人指定任务。 目标图像是一种流行的任务规格形式, 因为它们已经以机器人的观测空间为基础。 然而, 目标图像也有一些缺点: 它们对于人类来说不方便提供, 它们可以过度描述导致微薄的奖赏信号的预期行为, 或在非目标完成任务的情况下, 或对任务描述不够明确的任务信息。 自然语言为任务规范提供了方便和灵活的替代方法, 但随着机器人观察空间的地基语言的挑战而出现。 要大规模地学习这个基础性任务, 我们提议利用离线机器人数据集( 包括高度亚优度、 自主收集的数据) 来利用众源自然语言标签。 有了这些数据, 我们学习了一个简单的分类器, 预测状态变化是否完成一个非目标性任务。 这提供了一种语言调整的奖赏功能, 然后可以在离线的多塔级语言中定位语言中应用, 并且我们发现一个比正常的 Rtask 25 变的自然条件技术 。