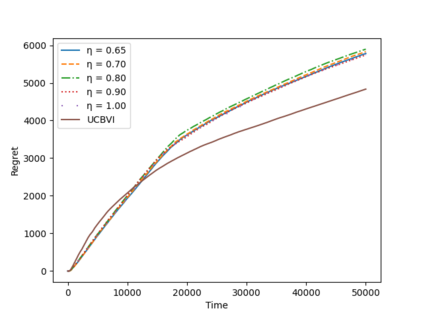
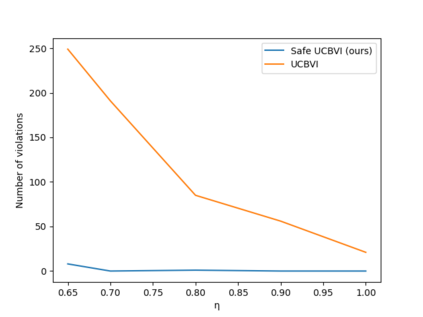
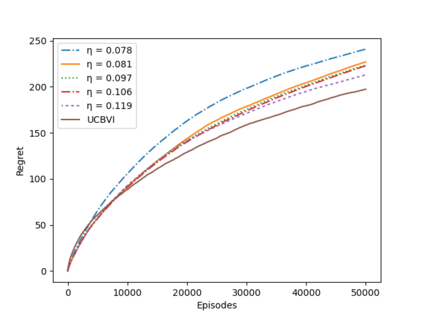
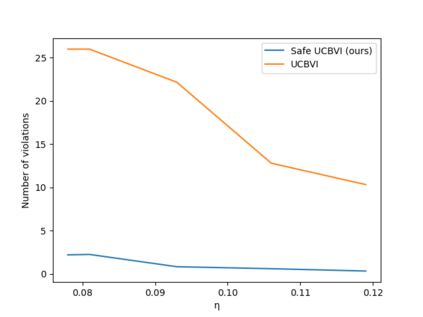
A key challenge to deploying reinforcement learning in practice is exploring safely. We propose a natural safety property -- \textit{uniformly} outperforming a conservative policy (adaptively estimated from all data observed thus far), up to a per-episode exploration budget. We then design an algorithm that uses a UCB reinforcement learning policy for exploration, but overrides it as needed to ensure safety with high probability. We experimentally validate our results on a sepsis treatment task, demonstrating that our algorithm can learn while ensuring good performance compared to the baseline policy for every patient.
翻译:在实践中部署强化学习的一个关键挑战是安全地探索。我们建议一种自然安全属性 -- -- \ textit{unificly}比保守政策(根据迄今所观察到的所有数据进行适当估计)表现得更好,直到每个单元的勘探预算。然后我们设计一种算法,在勘探时使用UCB强化学习政策,但根据需要,以高概率取代它,以确保安全。我们实验性地验证了我们关于Sepsis治疗任务的结果,表明我们的算法可以学习,同时确保每个病人与基线政策相比,表现良好。