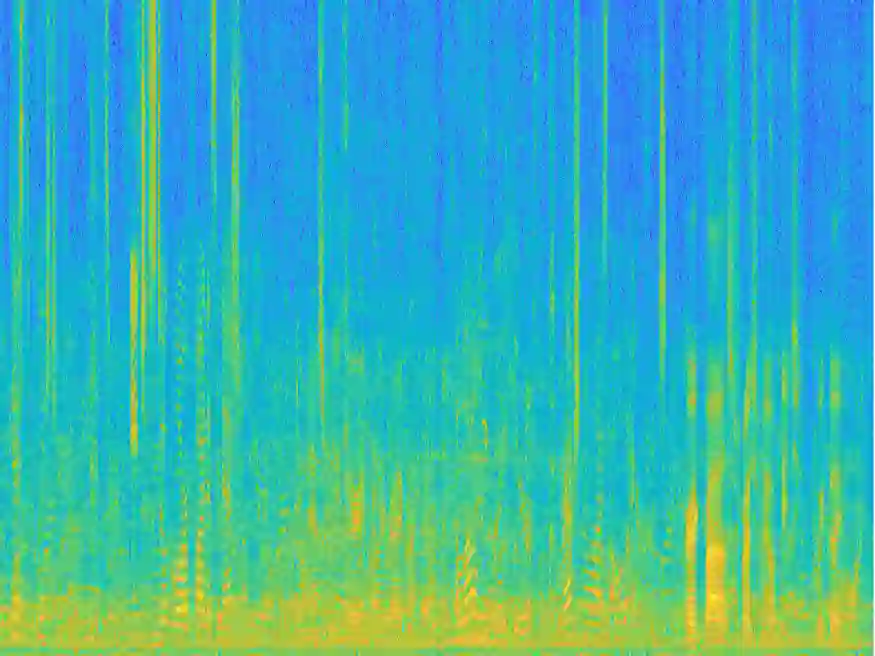
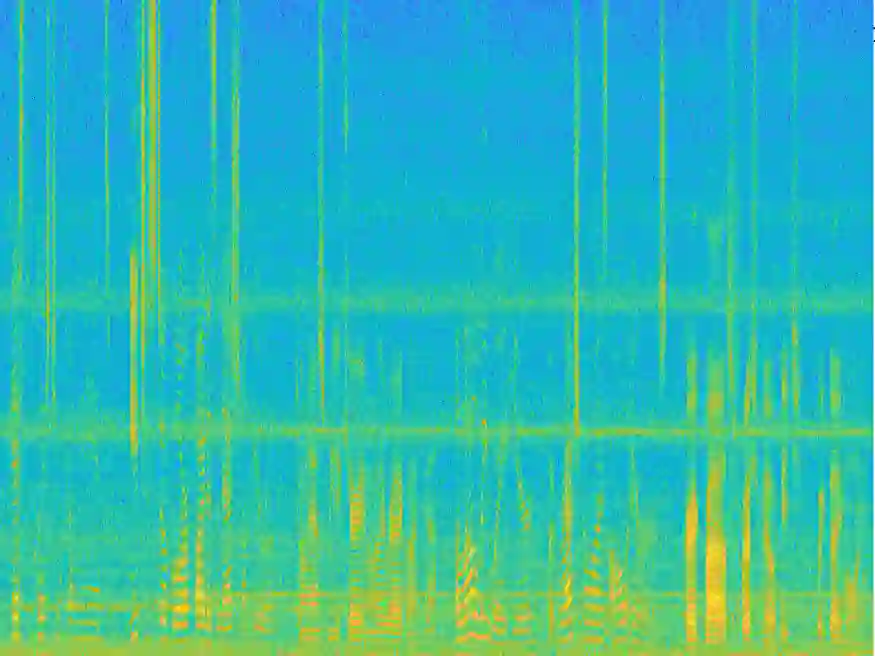
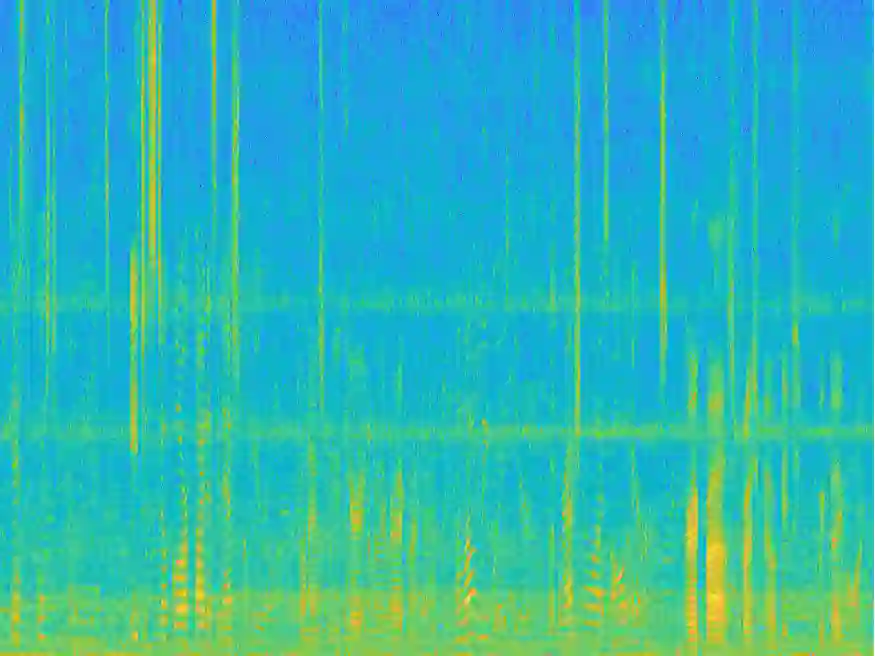
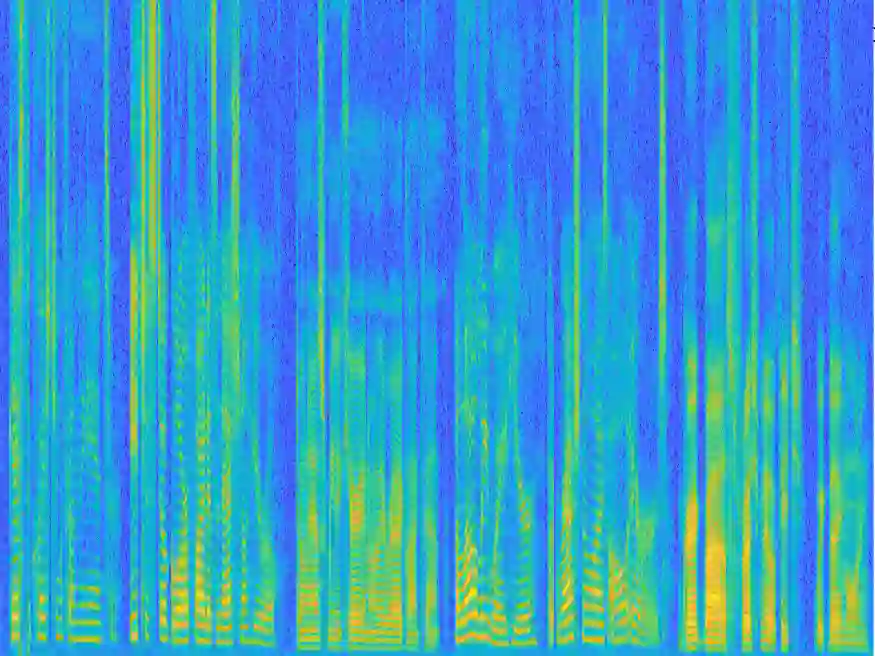
Recently, variational autoencoder (VAE), a deep representation learning (DRL) model, has been used to perform speech enhancement (SE). However, to the best of our knowledge, current VAE-based SE methods only apply VAE to the model speech signal, while noise is modeled using the traditional non-negative matrix factorization (NMF) model. One of the most important reasons for using NMF is that these VAE-based methods cannot disentangle the speech and noise latent variables from the observed signal. Based on Bayesian theory, this paper derives a novel variational lower bound for VAE, which ensures that VAE can be trained in supervision, and can disentangle speech and noise latent variables from the observed signal. This means that the proposed method can apply the VAE to model both speech and noise signals, which is totally different from the previous VAE-based SE works. More specifically, the proposed DRL method can learn to impose speech and noise signal priors to different sets of latent variables for SE. The experimental results show that the proposed method can not only disentangle speech and noise latent variables from the observed signal but also obtain a higher scale-invariant signal-to-distortion ratio and speech quality score than the similar deep neural network-based (DNN) SE method.
翻译:最近,变式自动读数器(VAE)是一种深层表达式学习(DRL)模型,已被用于进行语音增强。然而,据我们所知,目前基于VAE的SE方法仅将VAE应用到示范语音信号中,而噪音则使用传统的非负式矩阵因子化(NMF)模型进行模拟。使用NMF的最重要原因之一是这些基于VAE的方法无法将语音和噪音潜伏变量与观察到的信号分解开来。根据Bayesian理论,本文为VAE提供了一个新的更低的变数框,确保VAE在监督中接受培训,并且能够将语音和噪音潜伏变量与所观察到的信号信号信号信号分解开来。这意味着拟议方法可以将VAE用于模拟语音和噪音信号,这与以前基于VAE的SE工作完全不同。更具体地说,拟议的DRL方法可以学会在SEE的不同潜在变量之前将语音和噪音信号分解。实验结果显示,拟议的方法不仅能够将语音和低级语音质量的信号网络与所观测到的深级变数获得类似信号。