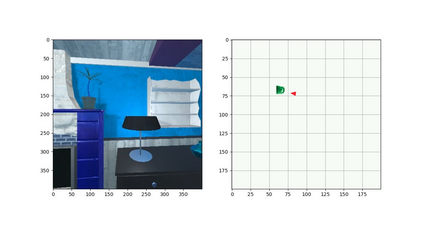
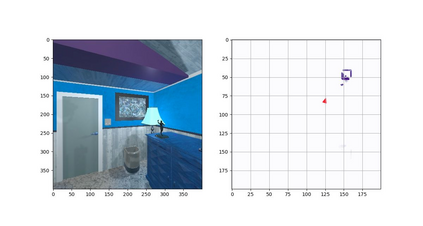
Robotic task instructions often involve a referred object that the robot must locate (ground) within the environment. While task intent understanding is an essential part of natural language understanding, less effort is made to resolve ambiguity that may arise while grounding the task. Existing works use vision-based task grounding and ambiguity detection, suitable for a fixed view and a static robot. However, the problem magnifies for a mobile robot, where the ideal view is not known beforehand. Moreover, a single view may not be sufficient to locate all the object instances in the given area, which leads to inaccurate ambiguity detection. Human intervention is helpful only if the robot can convey the kind of ambiguity it is facing. In this article, we present DoRO (Disambiguation of Referred Object), a system that can help an embodied agent to disambiguate the referred object by raising a suitable query whenever required. Given an area where the intended object is, DoRO finds all the instances of the object by aggregating observations from multiple views while exploring & scanning the area. It then raises a suitable query using the information from the grounded object instances. Experiments conducted with the AI2Thor simulator show that DoRO not only detects the ambiguity more accurately but also raises verbose queries with more accurate information from the visual-language grounding.
翻译:机器人在环境中必须定位( 地面) 的被推荐对象 。 虽然任务意图理解是自然语言理解的一个基本部分, 但任务对象理解是自然语言理解的一个必要部分, 但解决在任务定位时可能出现的模糊性的努力较少。 现有的作品使用基于视觉的任务定位和模糊性探测, 适合固定视图和静态机器人。 但是, 问题会放大到移动机器人, 理想视图事先并不知道。 此外, 单一观点可能不足以定位给定区域内的所有对象实例, 从而导致不准确的模糊性探测 。 只有当机器人能够传达它所面临的模糊性时, 人类的干预才有帮助 。 在文章中, 我们介绍 DoRO( 分解被推荐对象), 这个系统可以帮助一个具有内涵的代理人在需要时提出合适的查询来解析被推荐对象 。 在指定对象所在的区域, DoRO 会通过从多个视图中汇总观测结果, 来查找该对象的所有实例, 从而导致不准确的模糊性检测 。 然后, 使用有根物体实例的信息来进行适当的查询 。 与 AI2Thoosever imulator 进行实验, 更准确的图像查询 。