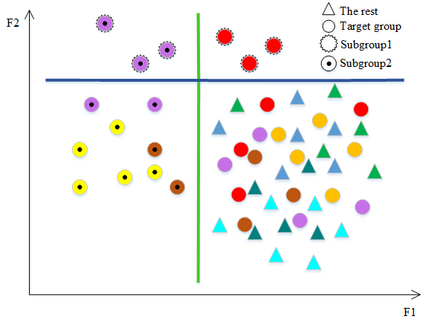
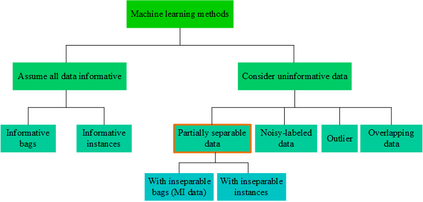
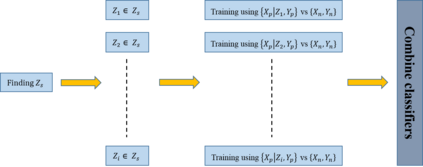
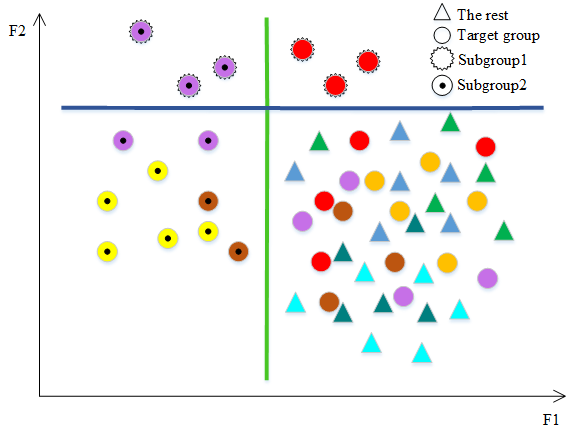
There are partially separable data types that make classification tasks very hard. In other words, only parts of the data are informative meaning that looking at the rest of the data would not give any distinguishable hint for classification. In this situation, the typical assumption of having the whole labeled data as an informative unit set for classification does not work. Consequently, typical classification methods with the mentioned assumption fail in such a situation. In this study, we propose a framework for the classification of partially separable data types that are not classifiable using typical methods. An algorithm based on the framework is proposed that tries to detect separable subgroups of the data using an iterative clustering approach. Then the detected subgroups are used in the classification process. The proposed approach was tested on a real dataset for autism screening and showed its capability by distinguishing children with autism from normal ones, while the other methods failed to do so.
翻译:有部分可分离的数据类型使得分类任务非常困难。换句话说,只有部分数据是信息化的,这意味着看其余数据不会给分类带来任何可区分的提示。在这种情况下,将整个标签数据作为信息单位进行分类的典型假设是行不通的。因此,有上述假设的典型分类方法在这种情况下失败了。在本研究中,我们建议了一个框架,用于对部分可分离的数据类型进行分类,而不能使用典型方法进行分类。基于框架的算法建议试图用迭代组合法来探测数据中可分离的分组。然后,在分类过程中使用被检测到的分组。拟议方法是在自闭症筛查的真实数据集上测试的,通过区分自闭症儿童和正常儿童来显示其能力,而其他方法则未能这样做。