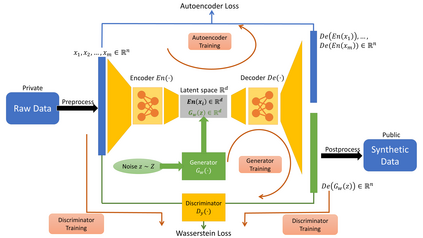
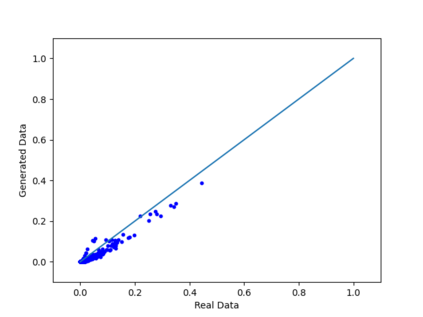
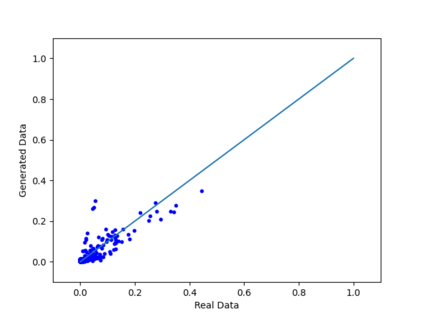
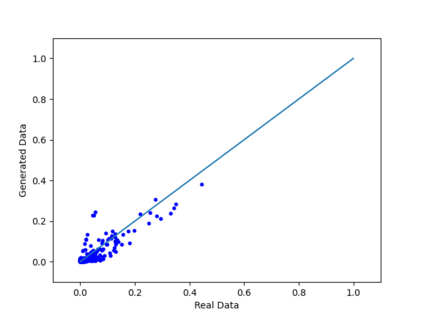
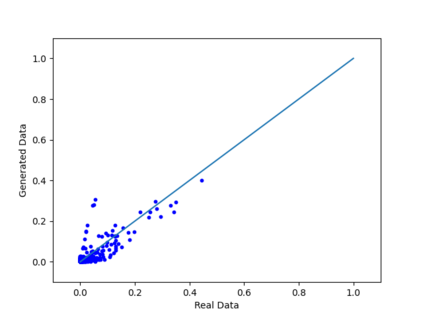
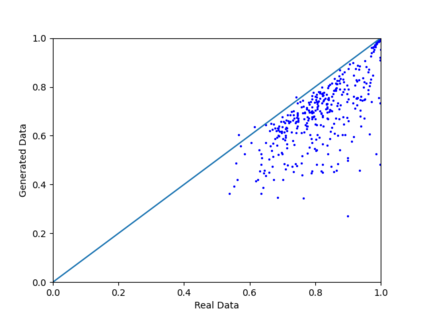
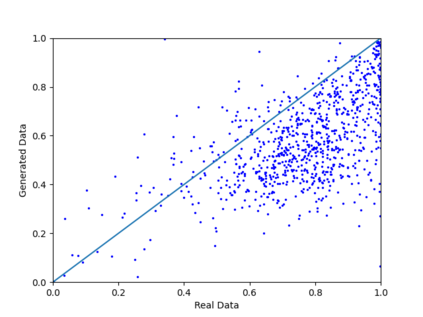
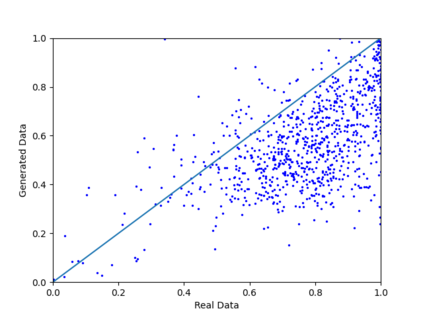
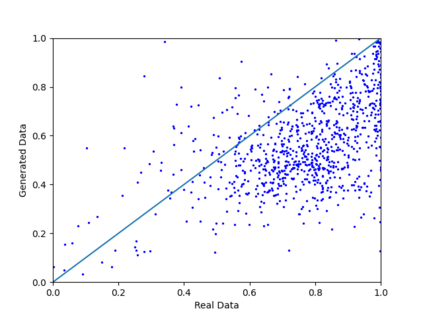
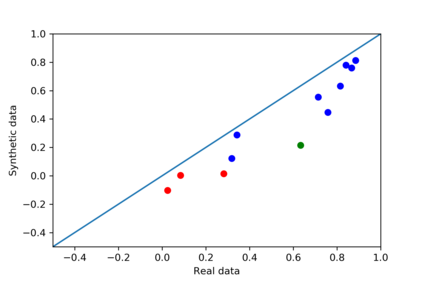
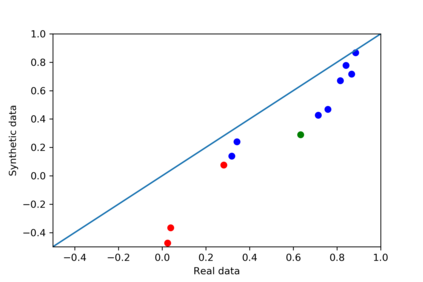
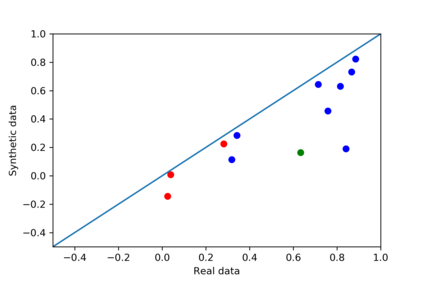
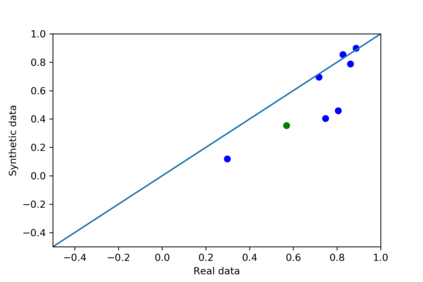
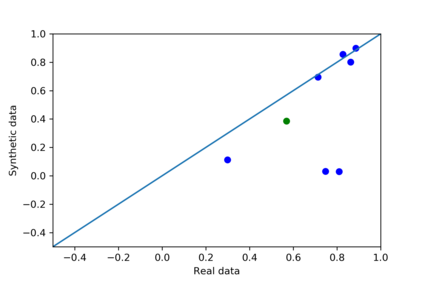
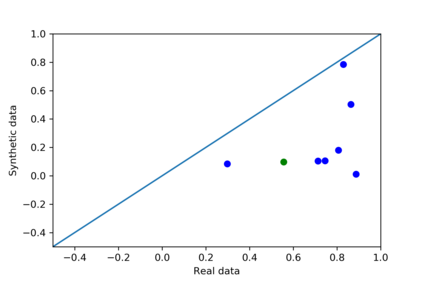
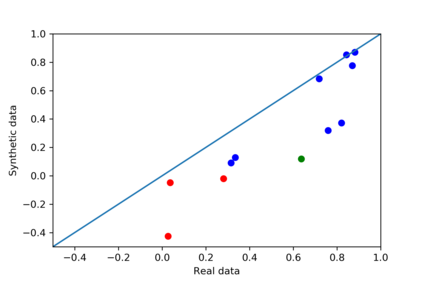
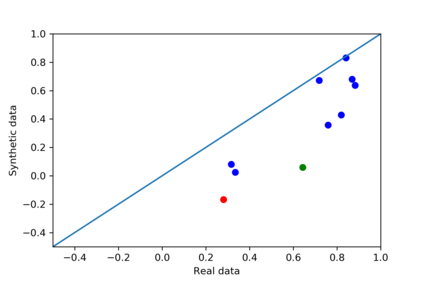
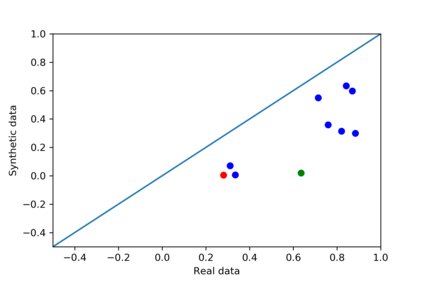
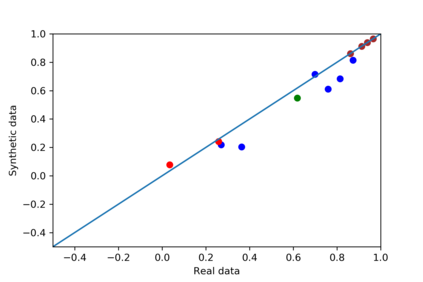
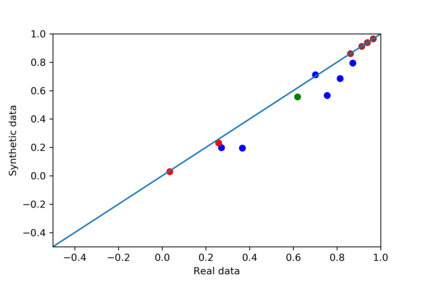
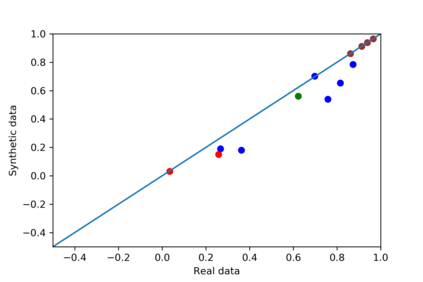
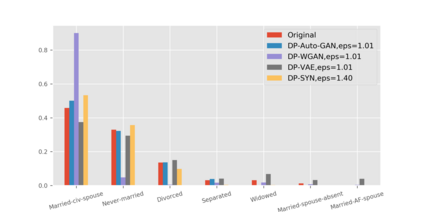
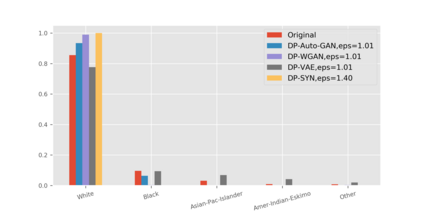
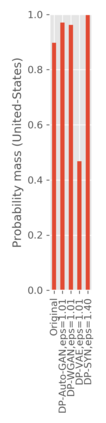
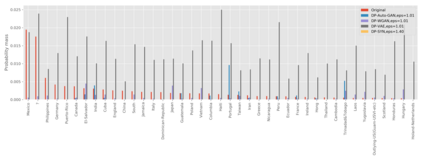
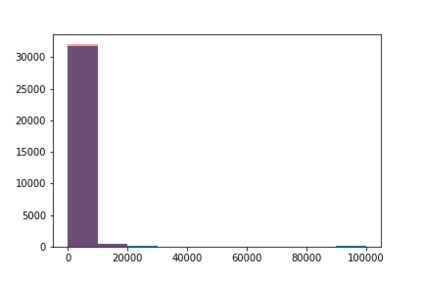
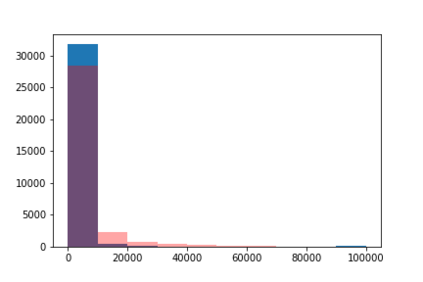
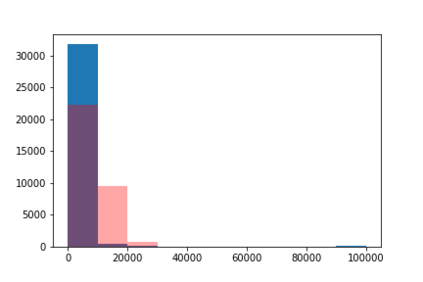
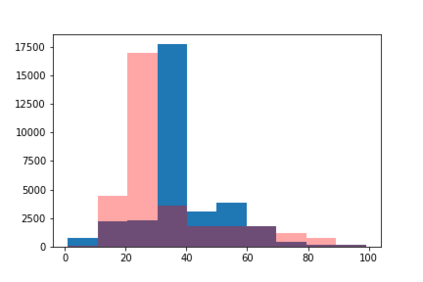
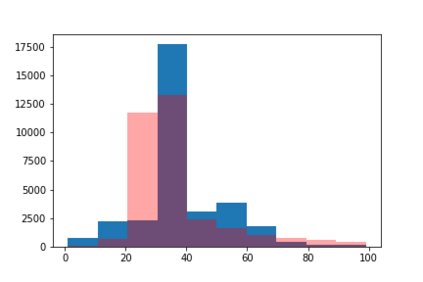
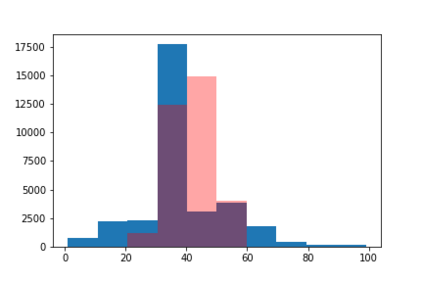
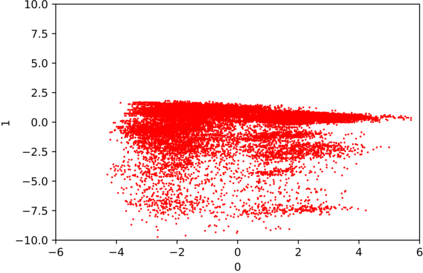
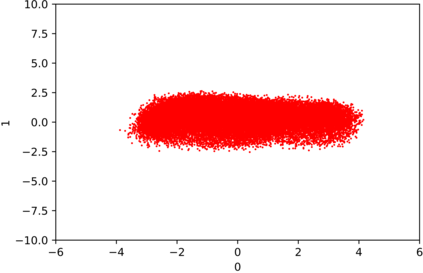
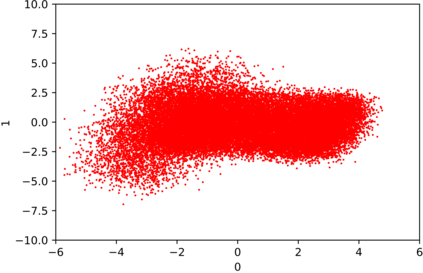
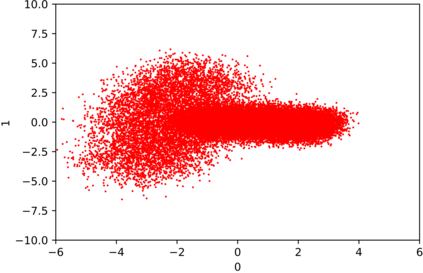
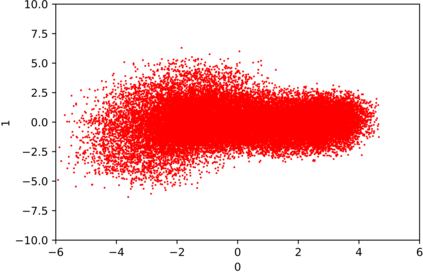
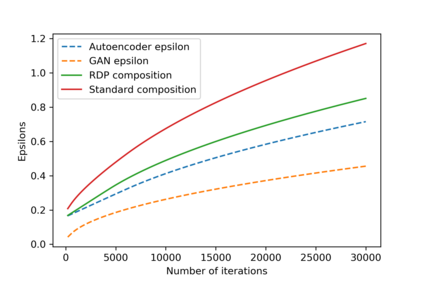
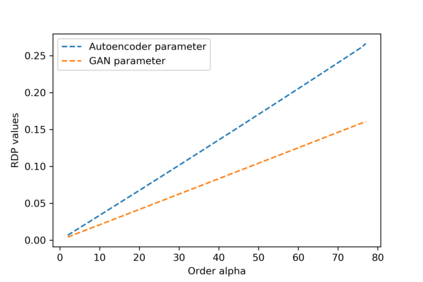
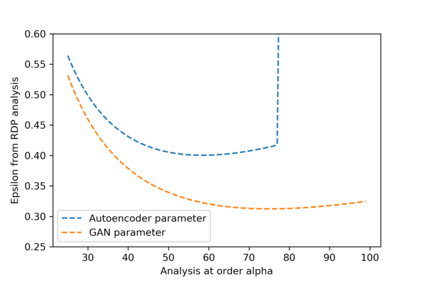
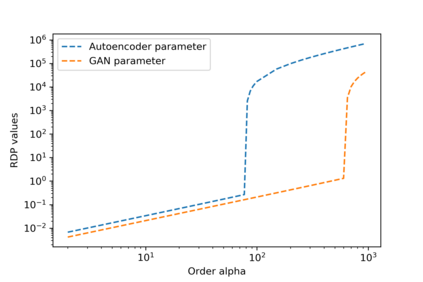
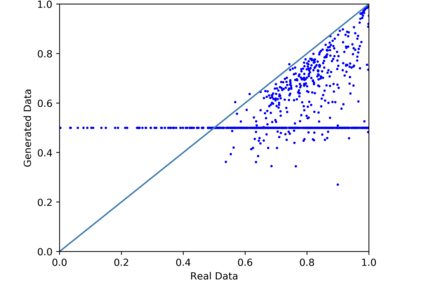
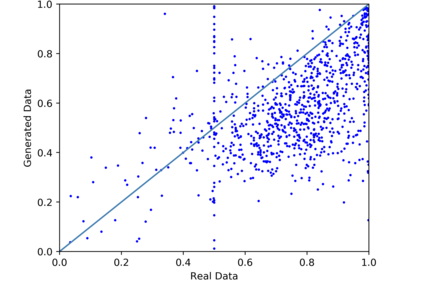
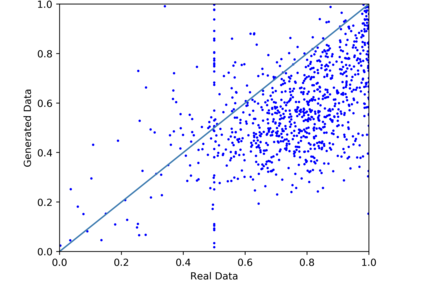
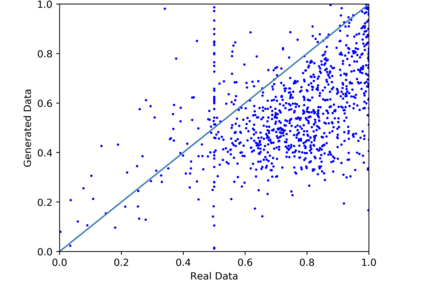
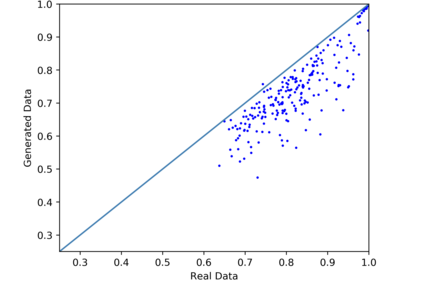
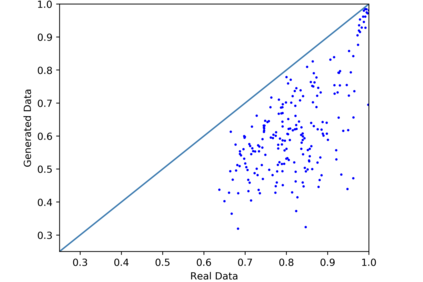
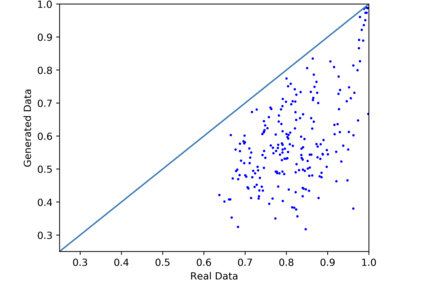
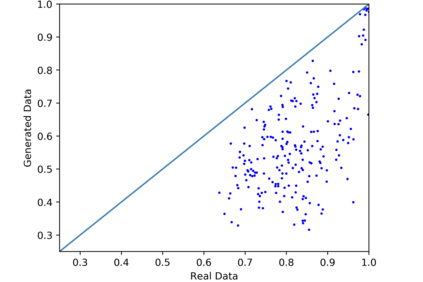
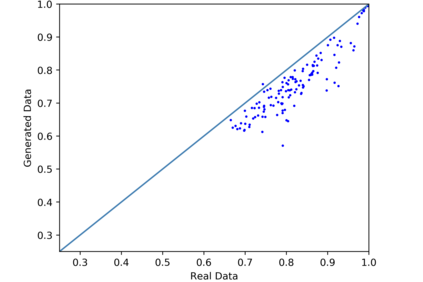
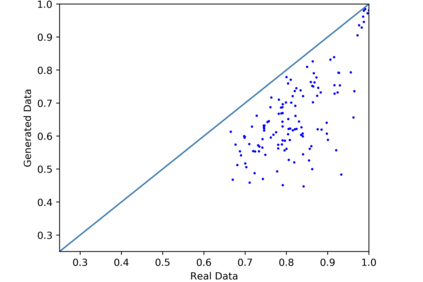
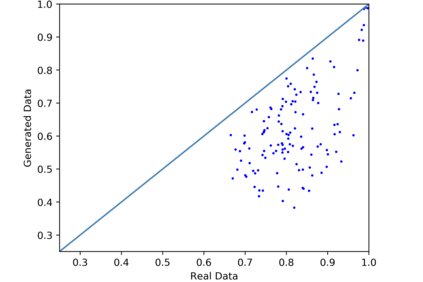
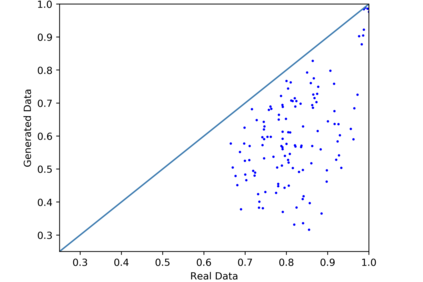
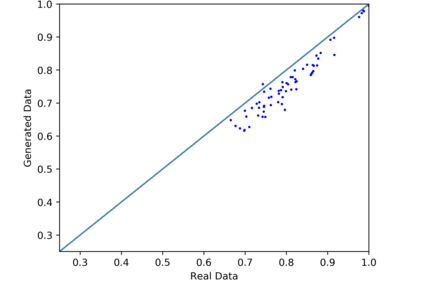
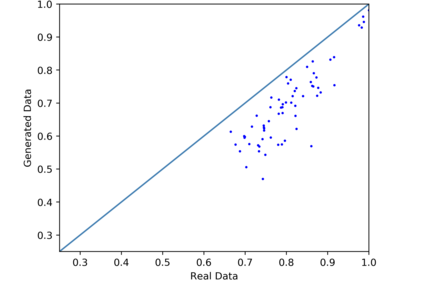
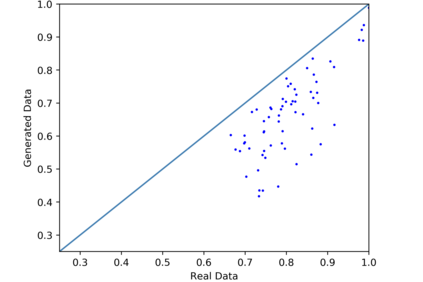
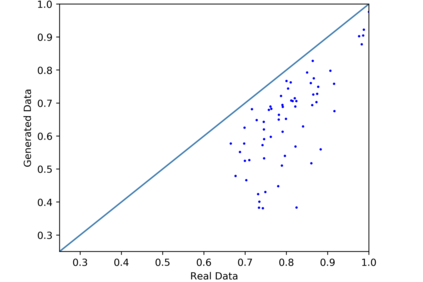
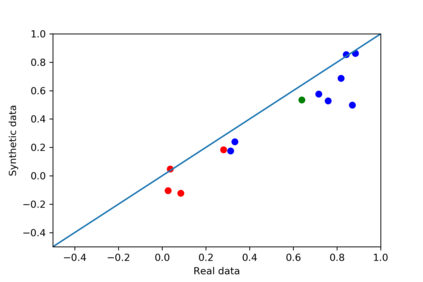
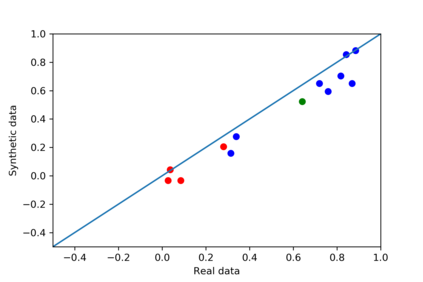
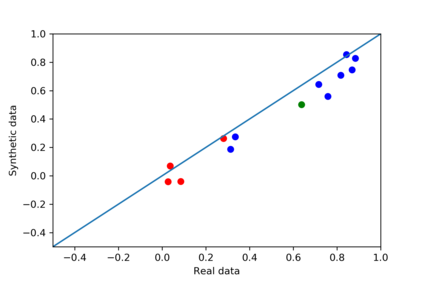
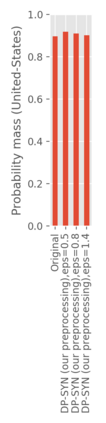
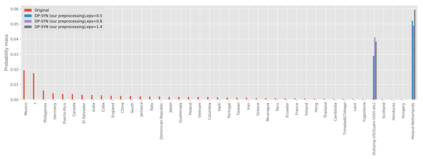
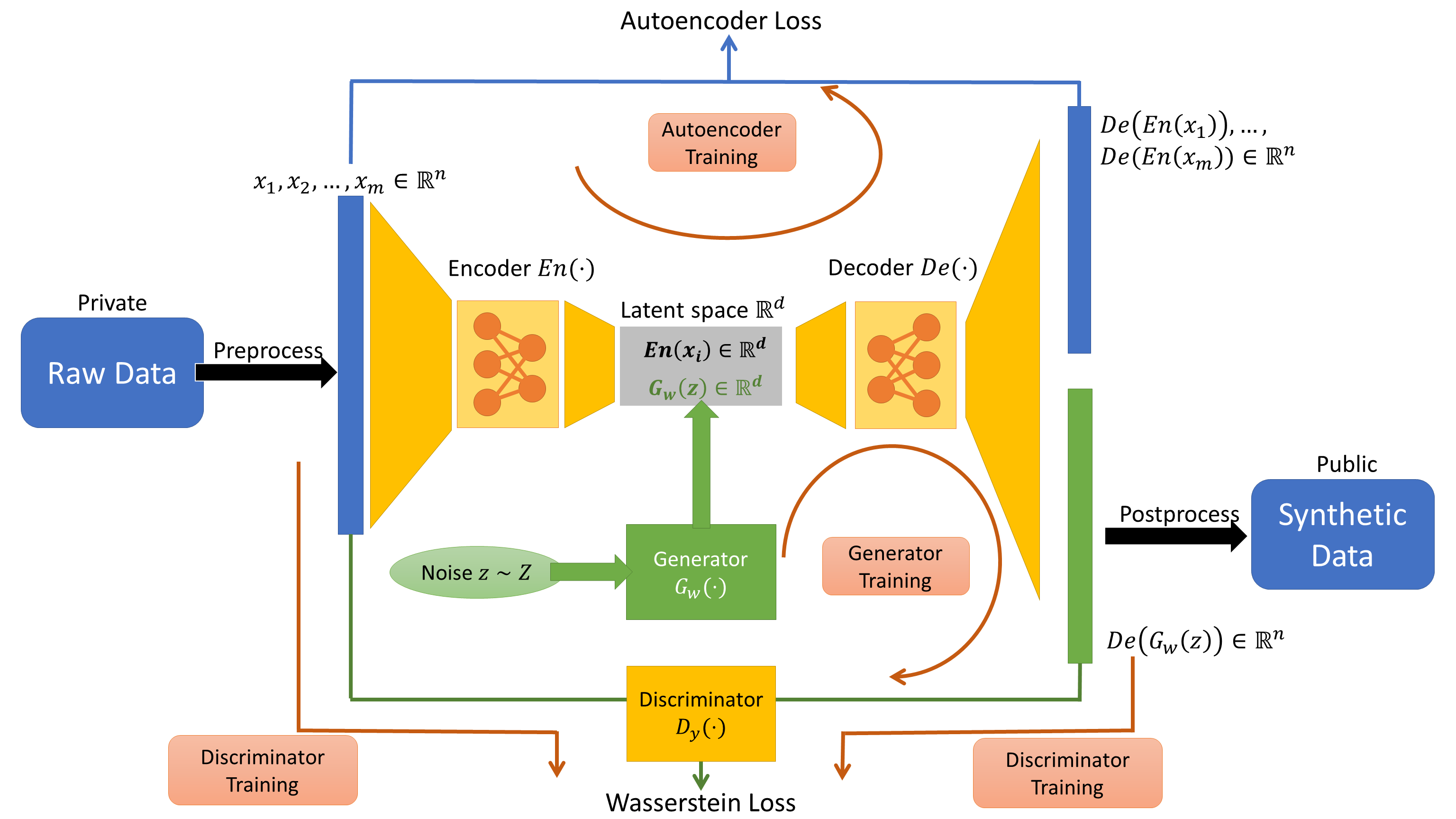
We introduce the DP-auto-GAN framework for synthetic data generation, which combines the low dimensional representation of autoencoders with the flexibility of Generative Adversarial Networks (GANs). This framework can be used to take in raw sensitive data and privately train a model for generating synthetic data that will satisfy similar statistical properties as the original data. This learned model can generate an arbitrary amount of synthetic data, which can then be freely shared due to the post-processing guarantee of differential privacy. Our framework is applicable to unlabeled mixed-type data, that may include binary, categorical, and real-valued data. We implement this framework on both binary data (MIMIC-III) and mixed-type data (ADULT), and compare its performance with existing private algorithms on metrics in unsupervised settings. We also introduce a new quantitative metric able to detect diversity, or lack thereof, of synthetic data.
翻译:我们引入了用于合成数据生成的DP-auto-GAN框架,这一框架将自动编码器的低维代表性与基因反转网络(GANs)的灵活性结合起来,可以用于原始敏感数据和私人培训生成合成数据的模型,这种模型将满足原始数据的类似统计特性,这种学习模式可以产生任意数量的合成数据,然后由于处理后对不同隐私的保证,可以自由分享这些数据。我们的框架适用于无标签的混合型数据,其中可能包括二元数据、绝对数据以及实际价值的数据。我们实施这一框架,既包括二元数据(MIMIC-III),也包括混合型数据(ADULT),并将这一框架的性能与在不受监督的环境中测量的现有私人算法进行比较。我们还引入新的定量指标,能够检测合成数据的多样性或缺乏多样性。