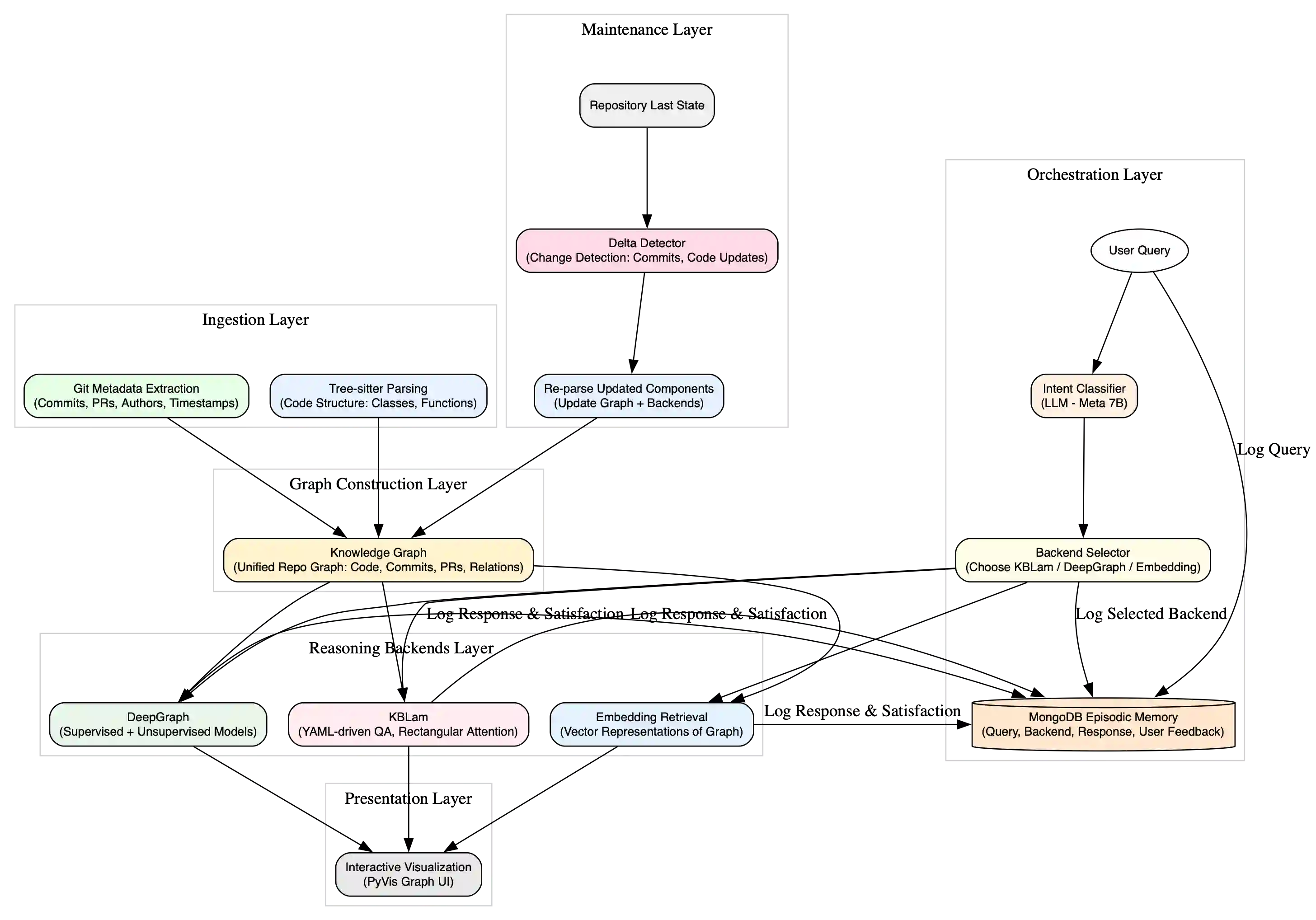
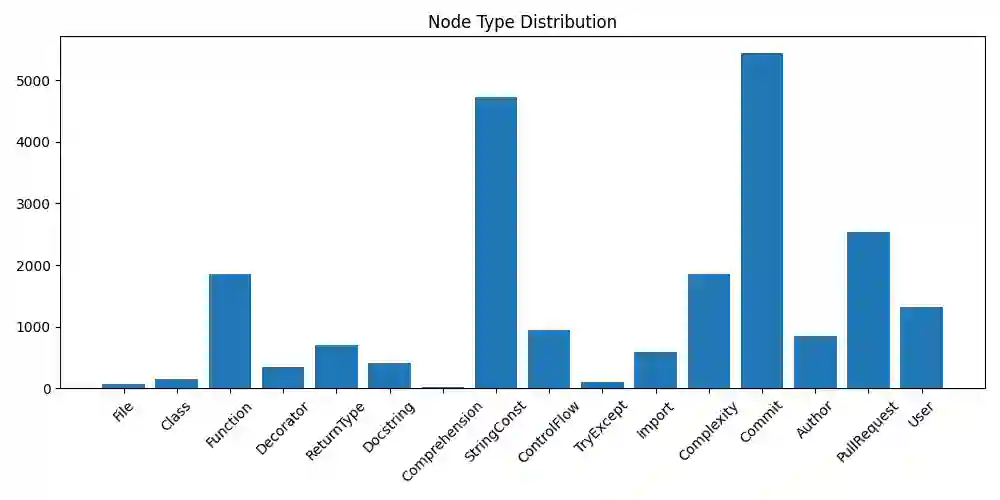
Modern enterprises manage vast knowledge distributed across heterogeneous systems such as Jira, Git repositories, Confluence, and wikis. Conventional retrieval methods based on keyword search or static embeddings often fail to answer complex queries that require contextual reasoning and multi-hop inference across artifacts. We present a modular hybrid retrieval framework for adaptive enterprise information access that integrates Knowledge Base Language-Augmented Models (KBLam), DeepGraph representations, and embedding-driven semantic search. The framework builds a unified knowledge graph from parsed repositories including code, pull requests, and commit histories, enabling semantic similarity search, structural inference, and multi-hop reasoning. Query analysis dynamically determines the optimal retrieval strategy, supporting both structured and unstructured data sources through independent or fused processing. An interactive interface provides graph visualizations, subgraph exploration, and context-aware query routing to generate concise and explainable answers. Experiments on large-scale Git repositories show that the unified reasoning layer improves answer relevance by up to 80 percent compared with standalone GPT-based retrieval pipelines. By combining graph construction, hybrid reasoning, and interactive visualization, the proposed framework offers a scalable, explainable, and user-centric foundation for intelligent knowledge assistants in enterprise environments.
翻译:暂无翻译