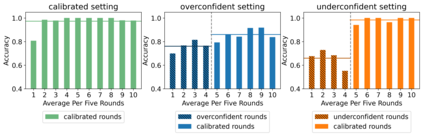
As natural language becomes the default interface for human-AI interaction, there is a critical need for LMs to appropriately communicate uncertainties in downstream applications. In this work, we investigate how LMs incorporate confidence about their responses via natural language and how downstream users behave in response to LM-articulated uncertainties. We examine publicly deployed models and find that LMs are unable to express uncertainties when answering questions even when they produce incorrect responses. LMs can be explicitly prompted to express confidences, but tend to be overconfident, resulting in high error rates (on average 47%) among confident responses. We test the risks of LM overconfidence by running human experiments and show that users rely heavily on LM generations, whether or not they are marked by certainty. Lastly, we investigate the preference-annotated datasets used in RLHF alignment and find that humans have a bias against texts with uncertainty. Our work highlights a new set of safety harms facing human-LM interactions and proposes design recommendations and mitigating strategies moving forward.
翻译:暂无翻译