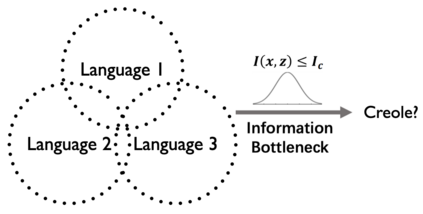
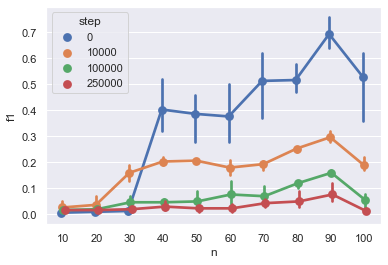
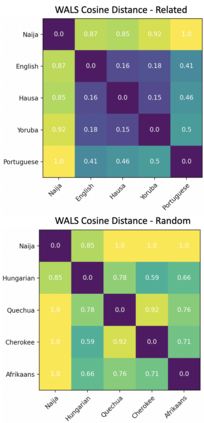
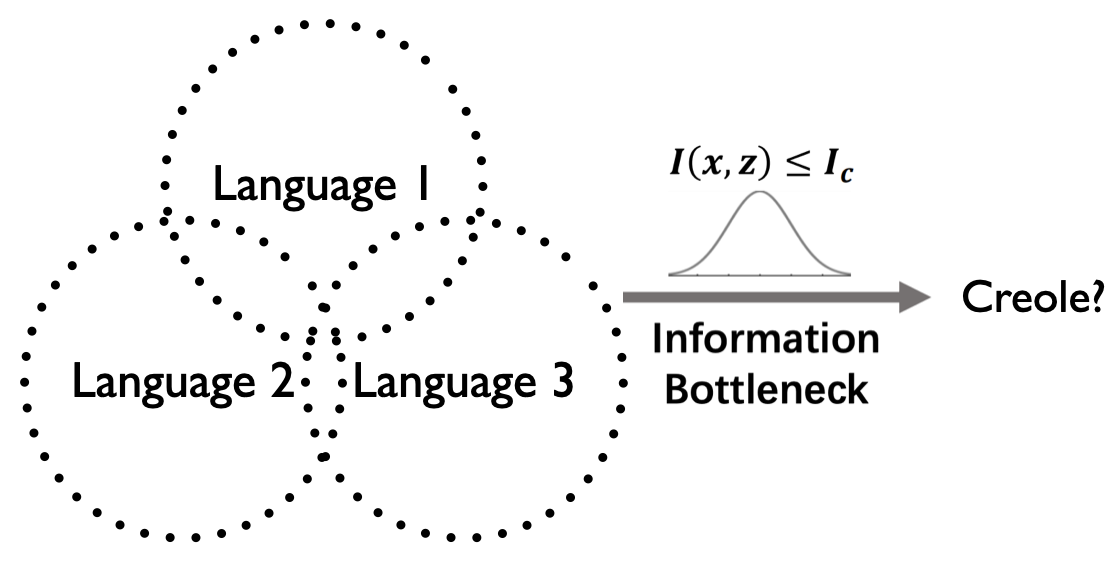
We aim to learn language models for Creole languages for which large volumes of data are not readily available, and therefore explore the potential transfer from ancestor languages (the 'Ancestry Transfer Hypothesis'). We find that standard transfer methods do not facilitate ancestry transfer. Surprisingly, different from other non-Creole languages, a very distinct two-phase pattern emerges for Creoles: As our training losses plateau, and language models begin to overfit on their source languages, perplexity on the Creoles drop. We explore if this compression phase can lead to practically useful language models (the 'Ancestry Bottleneck Hypothesis'), but also falsify this. Moreover, we show that Creoles even exhibit this two-phase pattern even when training on random, unrelated languages. Thus Creoles seem to be typological outliers and we speculate whether there is a link between the two observations.
翻译:我们的目标是学习克里奥尔语的语言模式,因为对于克里奥尔语来说,大量数据并不容易获得,因此我们探索了从祖先语言(“祖先转移假说 ” ) 转移的可能性。我们发现标准转移方法无助于祖先的转移。 奇怪的是,与其他非克里奥尔语言不同,克里奥尔语出现了一种截然不同的两阶段模式:随着我们的培训损失高地,语言模式开始过度适应其源语言,克里奥尔语的困惑程度下降。我们探索这一压缩阶段是否会导致实用的语言模式(“祖先转移假说 ” ), 但也假造了这一模式。 此外,我们证明克里奥尔人甚至展示了这种两阶段模式,即使是随机的、不相关的语言培训。因此克里奥尔语似乎是打字的异端,我们推测这两种观察之间是否有联系。