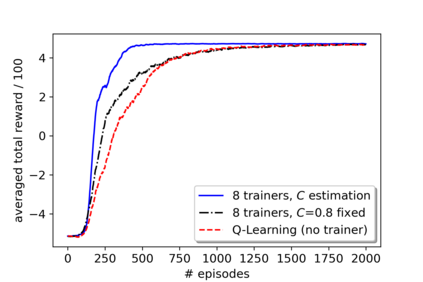
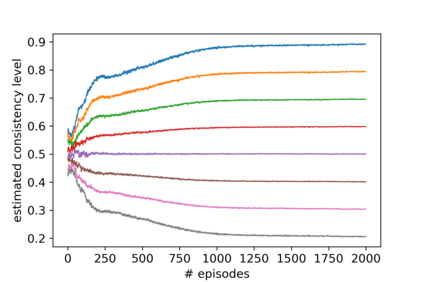
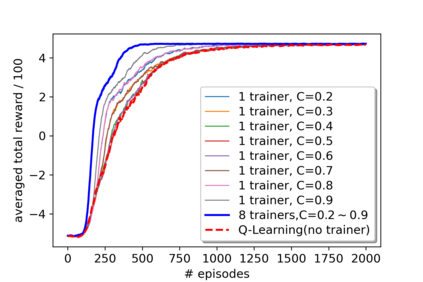
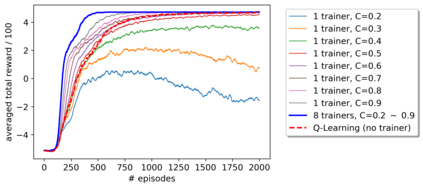
A promising approach to improve the robustness and exploration in Reinforcement Learning is collecting human feedback and that way incorporating prior knowledge of the target environment. It is, however, often too expensive to obtain enough feedback of good quality. To mitigate the issue, we aim to rely on a group of multiple experts (and non-experts) with different skill levels to generate enough feedback. Such feedback can therefore be inconsistent and infrequent. In this paper, we build upon prior work -- Advise, a Bayesian approach attempting to maximise the information gained from human feedback -- extending the algorithm to accept feedback from this larger group of humans, the trainers, while also estimating each trainer's reliability. We show how aggregating feedback from multiple trainers improves the total feedback's accuracy and make the collection process easier in two ways. Firstly, this approach addresses the case of some of the trainers being adversarial. Secondly, having access to the information about each trainer reliability provides a second layer of robustness and offers valuable information for people managing the whole system to improve the overall trust in the system. It offers an actionable tool for improving the feedback collection process or modifying the reward function design if needed. We empirically show that our approach can accurately learn the reliability of each trainer correctly and use it to maximise the information gained from the multiple trainers' feedback, even if some of the sources are adversarial.
翻译:改善强化学习的稳健性和探索的有希望的方法是收集人类反馈,并以此纳入对目标环境的先前知识。然而,往往过于昂贵,难以获得质量高的足够反馈。为了缓解这一问题,我们的目标是依靠一个技能水平不同的多专家(和非专家)小组,以产生足够的反馈。因此,这种反馈可能是不一致和少见的。在本文件中,我们以先前的工作 -- -- 咨询 -- -- 一种试图尽量扩大从人类反馈中获得的信息的巴耶斯方法为基础 -- -- 扩大算法,以接受来自这个更大的人类群体,即培训员的反馈,同时估计每个培训员的可靠性。我们展示了来自多个培训员的汇总反馈如何提高总反馈的准确性,使收集过程以两种方式更加容易。首先,这种方法涉及一些培训员处于对抗状态的情况。第二,获得关于每个培训员可靠性的信息提供了第二层的稳健性,为管理整个系统的人提供了宝贵的信息,以提高整个系统的总体信任度。它提供了一个可操作的工具,用于改进反馈收集过程或在必要时修改奖励功能的设计。我们的经验性地展示了每一个培训员的可靠性,如果能够正确学习,那么,那么,那么,我们每个培训员的可靠性地学习。