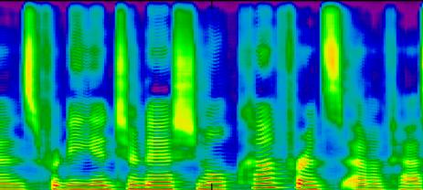
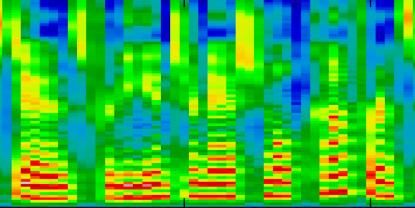
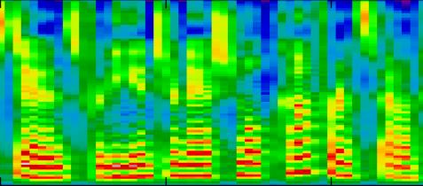
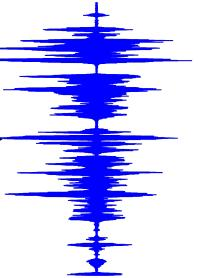
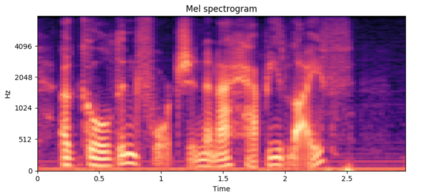
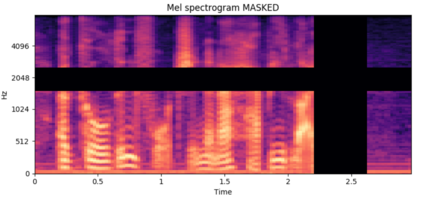
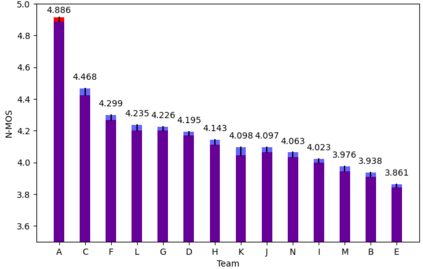
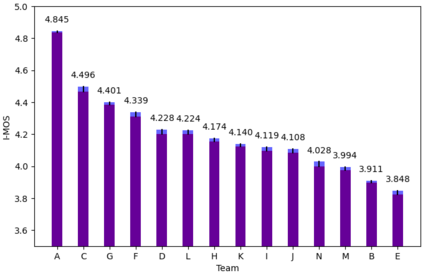
Recently, deep learning-based Text-to-Speech (TTS) systems have achieved high-quality speech synthesis results. Recurrent neural networks have become a standard modeling technique for sequential data in TTS systems and are widely used. However, training a TTS model which includes RNN components requires powerful GPU performance and takes a long time. In contrast, CNN-based sequence synthesis techniques can significantly reduce the parameters and training time of a TTS model while guaranteeing a certain performance due to their high parallelism, which alleviate these economic costs of training. In this paper, we propose a lightweight TTS system based on deep convolutional neural networks, which is a two-stage training end-to-end TTS model and does not employ any recurrent units. Our model consists of two stages: Text2Spectrum and SSRN. The former is used to encode phonemes into a coarse mel spectrogram and the latter is used to synthesize the complete spectrum from the coarse mel spectrogram. Meanwhile, we improve the robustness of our model by a series of data augmentations, such as noise suppression, time warping, frequency masking and time masking, for solving the low resource mongolian problem. Experiments show that our model can reduce the training time and parameters while ensuring the quality and naturalness of the synthesized speech compared to using mainstream TTS models. Our method uses NCMMSC2022-MTTSC Challenge dataset for validation, which significantly reduces training time while maintaining a certain accuracy.
翻译:暂无翻译