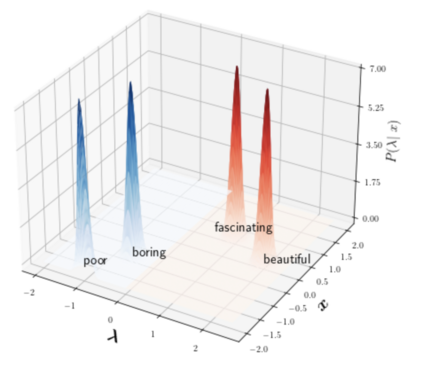
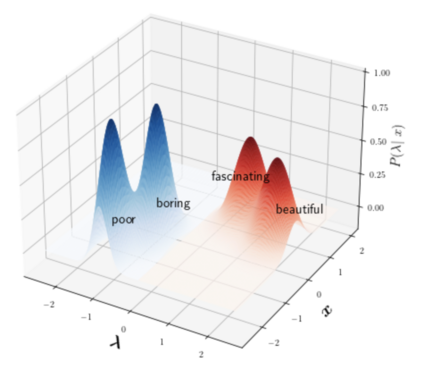
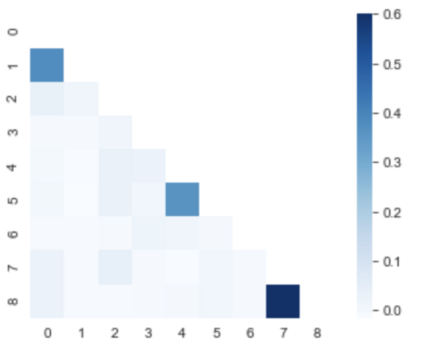
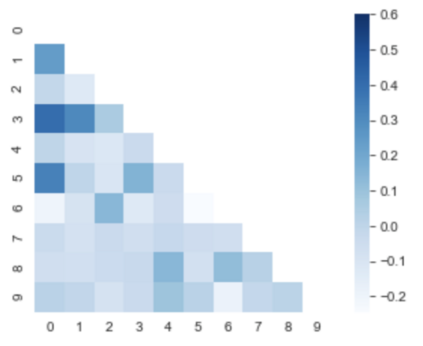
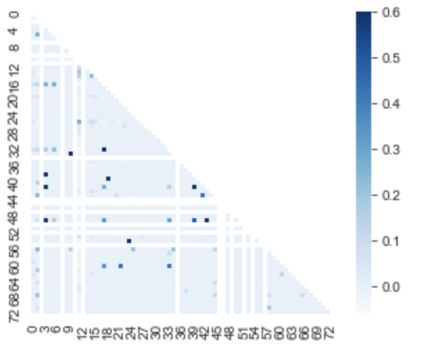
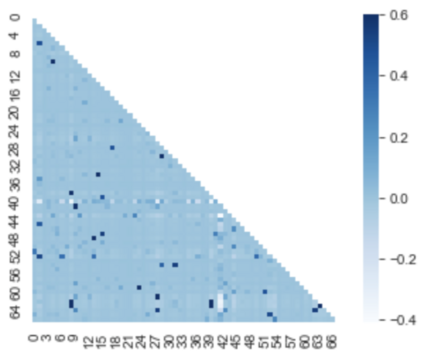
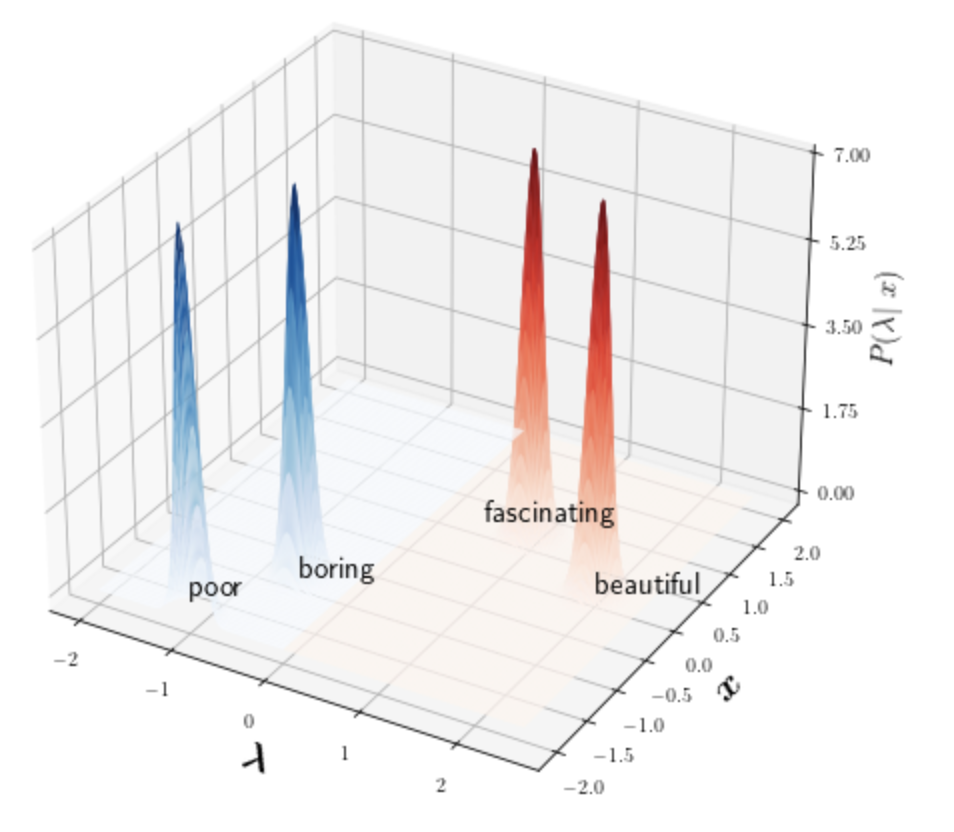
A popular approach to decrease the need for costly manual annotation of large data sets is weak supervision, which introduces problems of noisy labels, coverage and bias. Methods for overcoming these problems have either relied on discriminative models, trained with cost functions specific to weak supervision, and more recently, generative models, trying to model the output of the automatic annotation process. In this work, we explore a novel direction of generative modeling for weak supervision: Instead of modeling the output of the annotation process (the labeling function matches), we generatively model the input-side data distributions (the feature space) covered by labeling functions. Specifically, we estimate a density for each weak labeling source, or labeling function, by using normalizing flows. An integral part of our method is the flow-based modeling of multiple simultaneously matching labeling functions, and therefore phenomena such as labeling function overlap and correlations are captured. We analyze the effectiveness and modeling capabilities on various commonly used weak supervision data sets, and show that weakly supervised normalizing flows compare favorably to standard weak supervision baselines.
翻译:减少对大型数据集进行昂贵人工批注需要的流行做法是监督不力,这带来了吵闹标签、覆盖和偏差等问题。解决这些问题的方法要么依靠歧视模式,经过培训,具有监督不力所特有的成本功能,而最近又依靠基因模型,试图模拟自动批注过程的产出。在这项工作中,我们探索了为薄弱监督而采用基因化模型的新方向:我们没有模拟批注过程的产出(标签功能匹配),而是将标签功能所覆盖的输入-侧数据分布(特征空间)作为模型。具体地说,我们通过使用正常流来估计每个薄弱标签来源或标签功能的密度。我们方法的一个不可分割部分是多功能同时匹配标签功能的流基模型,因此,我们捕捉了标签功能重叠和关联等现象。我们分析了常见的各种薄弱监督数据集的有效性和建模能力,并表明,对薄弱的正常流量的监管比标准薄弱监督基线要好。