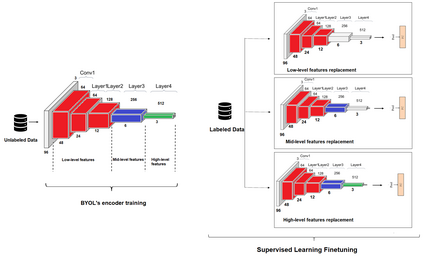
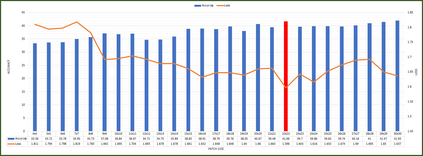
Supervised learning can learn large representational spaces, which are crucial for handling difficult learning tasks. However, due to the design of the model, classical image classification approaches struggle to generalize to new problems and new situations when dealing with small datasets. In fact, supervised learning can lose the location of image features which leads to supervision collapse in very deep architectures. In this paper, we investigate how self-supervision with strong and sufficient augmentation of unlabeled data can train effectively the first layers of a neural network even better than supervised learning, with no need for millions of labeled data. The main goal is to disconnect pixel data from annotation by getting generic task-agnostic low-level features. Furthermore, we look into Vision Transformers (ViT) and show that the low-level features derived from a self-supervised architecture can improve the robustness and the overall performance of this emergent architecture. We evaluated our method on one of the smallest open-source datasets STL-10 and we obtained a significant boost of performance from 41.66% to 83.25% when inputting low-level features from a self-supervised learning architecture to the ViT instead of the raw images.
翻译:受监督的学习可以学习巨大的代表空间,这对于处理困难的学习任务至关重要。然而,由于模型的设计,古典图像分类方法试图在处理小数据集时普及到新的问题和新情况。事实上,受监督的学习可能会失去图像特征的位置,从而导致非常深层的架构中的监督崩溃。在本文中,我们调查如何使用强力和足够的未加标签数据来有效培训神经网络的第一层,甚至比受监督的学习更好,不需要上百万个标签的数据。主要目标是通过获取普通任务不可知的低级别特征,将像素数据从批注中断开来。此外,我们查看视野变异器(Viet),并显示由自我监督的架构产生的低级别特征可以改善这一新兴架构的稳健性和总体性能。我们评估了我们关于最小的开放源数据集STL-10的方法,我们从41.66%到83.25 %的性能大幅提升,从自我监督的原始学习架构向ViT的原始图像输入低级别特征时,我们从41.66%到83.25%。