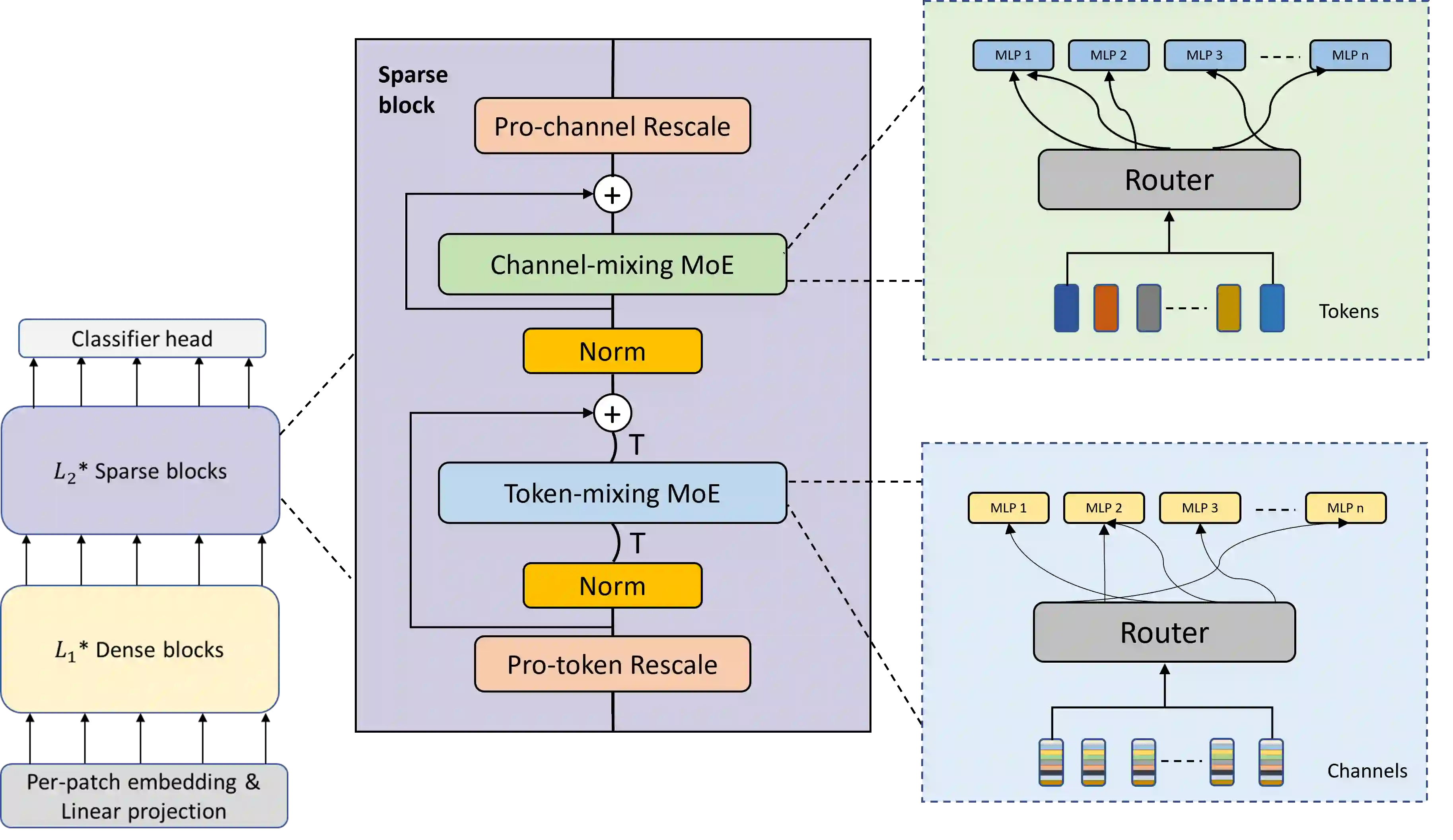
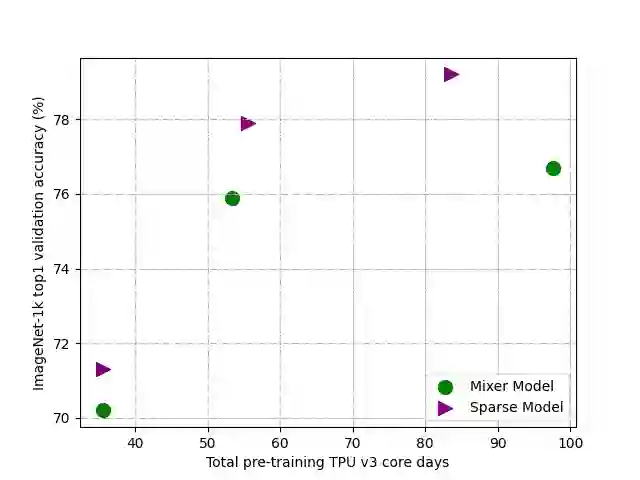
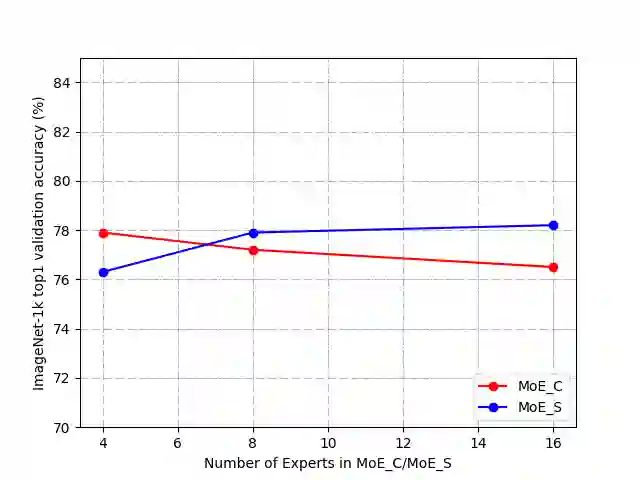
Mixture-of-Experts (MoE), a conditional computation architecture, achieved promising performance by scaling local module (i.e. feed-forward network) of transformer. However, scaling the cross-token module (i.e. self-attention) is challenging due to the unstable training. This work proposes Sparse-MLP, an all-MLP model which applies sparsely-activated MLPs to cross-token modeling. Specifically, in each Sparse block of our all-MLP model, we apply two stages of MoE layers: one with MLP experts mixing information within channels along image patch dimension, the other with MLP experts mixing information within patches along the channel dimension. In addition, by proposing importance-score routing strategy for MoE and redesigning the image representation shape, we further improve our model's computational efficiency. Experimentally, we are more computation-efficient than Vision Transformers with comparable accuracy. Also, our models can outperform MLP-Mixer by 2.5\% on ImageNet Top-1 accuracy with fewer parameters and computational cost. On downstream tasks, i.e. Cifar10 and Cifar100, our models can still achieve better performance than baselines.
翻译:专家混合模型(MOE)是一种有条件的计算结构,通过扩大变压器的本地模块(即进料向前网络),取得了有希望的绩效。然而,由于培训不稳定,扩大交叉点模块(即自我注意)具有挑战性。这项工作提出了Sprass-MLP,这是一个所有MLP模型,它应用了稀有活性 MLP 模型进行交叉式建模。具体地说,在我们所有MLP模型的每个小块中,我们应用了两个阶段的MOE层:一个是MLP专家,将频道内的信息与图像补接合,另一个是MLP专家,将信息与频道内的补接合。此外,通过为MOE提出重要点路标战略并重新设计图像显示形状,我们进一步提高了模型的计算效率。实验中,我们比具有类似精确度的Vision变压器更具计算效率。此外,我们的模型在图像网顶端-1的精度上比MLP-Mixer,2.5英寸比图像网络的精度高,其参数和计算成本比Ci10级模型还要高。