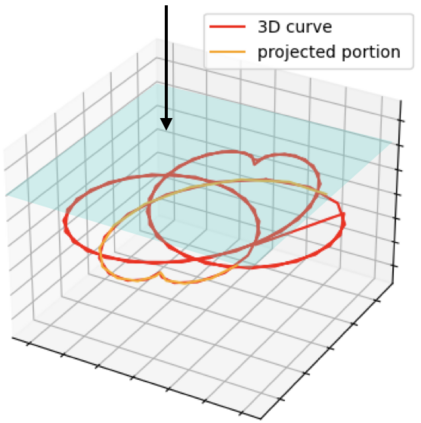
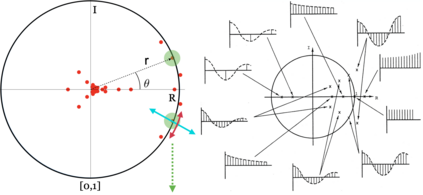
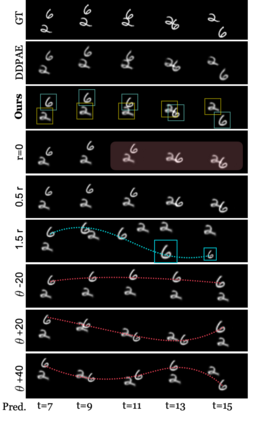
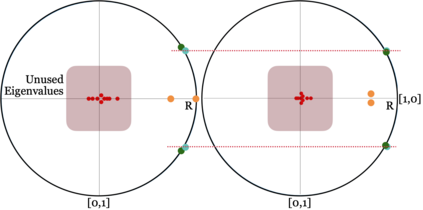
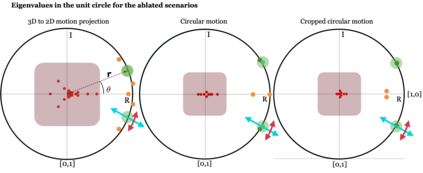
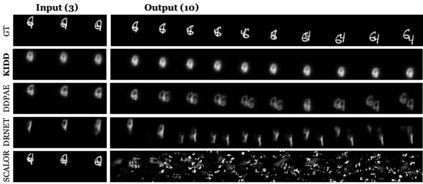
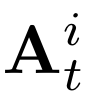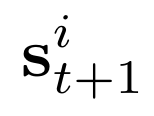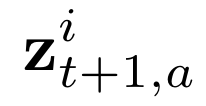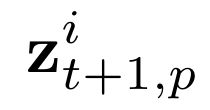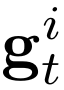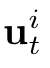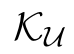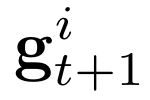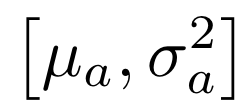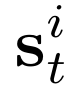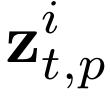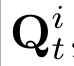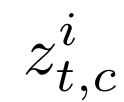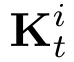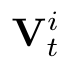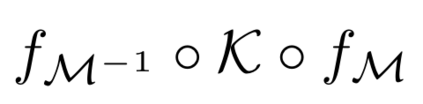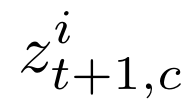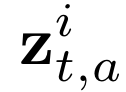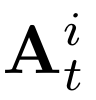Human interpretation of the world encompasses the use of symbols to categorize sensory inputs and compose them in a hierarchical manner. One of the long-term objectives of Computer Vision and Artificial Intelligence is to endow machines with the capacity of structuring and interpreting the world as we do. Towards this goal, recent methods have successfully been able to decompose and disentangle video sequences into their composing objects and dynamics, in a self-supervised fashion. However, there has been a scarce effort in giving interpretation to the dynamics of the scene. We propose a method to decompose a video into moving objects and their attributes, and model each object's dynamics with linear system identification tools, by means of a Koopman embedding. This allows interpretation, manipulation and extrapolation of the dynamics of the different objects by employing the Koopman operator K. We test our method in various synthetic datasets and successfully forecast challenging trajectories while interpreting them.
翻译:人类对世界的解释包括使用符号对感官输入进行分类,并以等级方式组成这些输入。计算机视觉和人工智能的长期目标之一是像我们这样做那样,将有能力构建和解释世界的机器投放。为了实现这一目标,最近的方法成功地以自我监督的方式将视频序列分解和分解成其组成对象和动态。然而,在解释场景动态方面,我们很少努力做出解释。我们提出了一个方法,将视频分解成移动对象及其属性,并通过Koopman嵌入工具,用线性系统识别工具模拟每个物体的动态。这样,我们就可以通过使用Koopman操作者K,对不同物体的动态进行解释、操纵和外推。我们在各种合成数据集中测试我们的方法,并成功地预测了在解释这些物体时对轨迹的挑战。