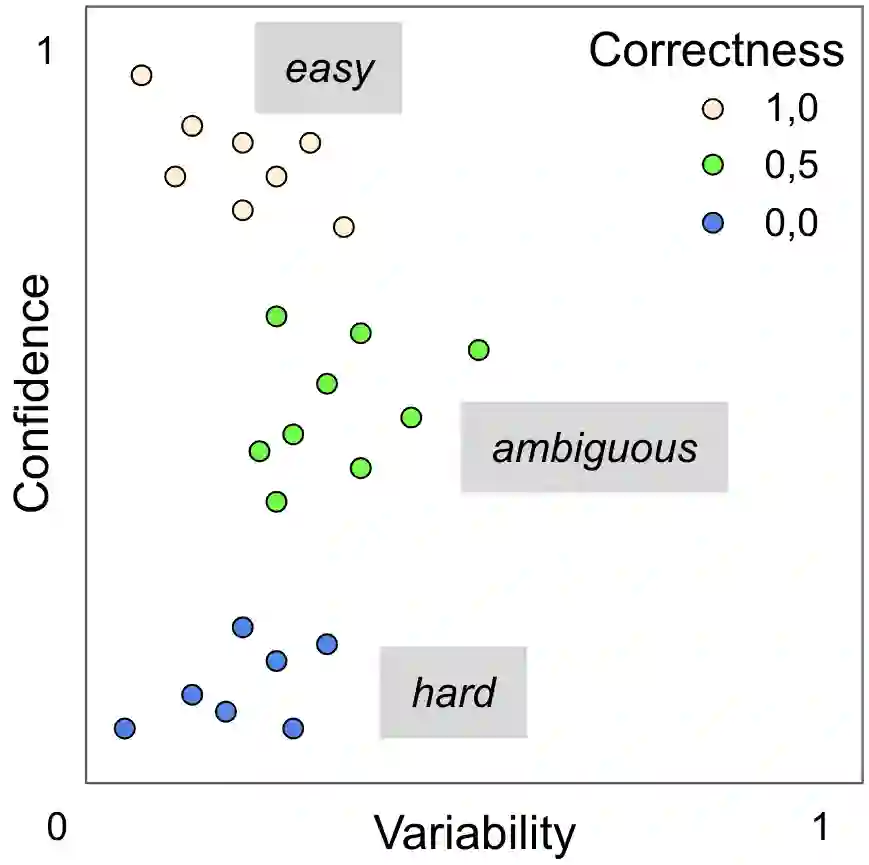
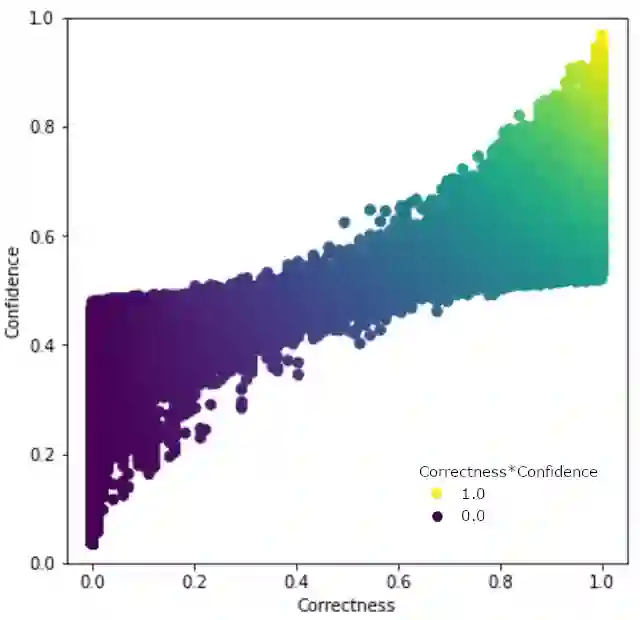
Real world datasets contain incorrectly labeled instances that hamper the performance of the model and, in particular, the ability to generalize out of distribution. Also, each example might have different contribution towards learning. This motivates studies to better understanding of the role of data instances with respect to their contribution in good metrics in models. In this paper we propose a method based on metrics computed from training dynamics of Gradient Boosting Decision Trees (GBDTs) to assess the behavior of each training example. We focus on datasets containing mostly tabular or structured data, for which the use of Decision Trees ensembles are still the state-of-the-art in terms of performance. We show results on detecting noisy labels in order to either remove them, improving models' metrics in synthetic and real datasets, as well as a productive dataset. Our methods achieved the best results overall when compared with confident learning and heuristics.
翻译:真实的世界数据集包含有错误的标签实例,妨碍模型的性能,特别是推广推广能力。此外,每个实例可能对学习有不同的贡献。这促使人们研究数据实例的作用,了解其对模型中良好指标的贡献。在本文中,我们提议了一种方法,其依据是,从“渐进推动决策树”的培训动态中计算出来的衡量尺度,以评估每个培训实例的行为。我们注重的数据集大多是表格或结构化数据,使用决策树组群仍然是业绩方面的最先进的数据。我们展示了探测噪音标签的结果,以便要么删除这些标签,改进合成和真实数据集中的模型指标,以及生产数据集。我们的方法与自信学习和超自然学相比,总体上取得了最佳的结果。