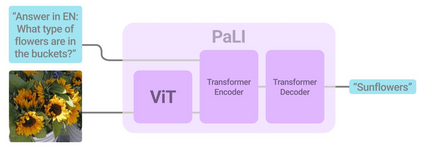
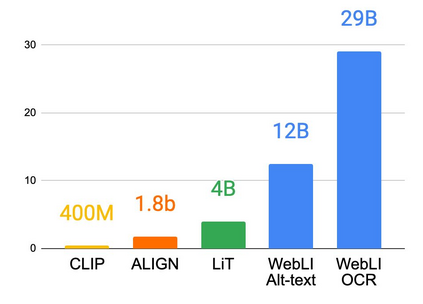
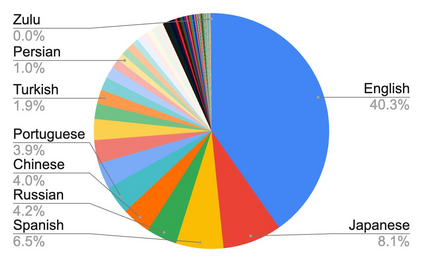
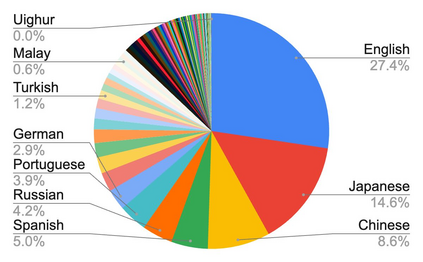
Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
翻译:有效缩放和灵活的任务界面使大型语言模型能够完成许多任务。 PaLI(Pathways语言和图像模型)将这一方法推广到语言和视觉的联合模型。 PALI生成基于视觉和文字投入的文本,并用多种语言执行许多视觉、语言和多式联运任务。为培训PLI,我们使用大型预先训练的编码脱coder语言模型和愿景变异器(ViTs),这使我们能够利用现有能力并利用培训它们的巨大成本。我们发现,共同缩放视觉和语言组成部分很重要。由于现有的语言变换器比其视觉对等器要大得多,我们培训迄今为止最大的VIT(ViT-e),以量化甚至更大型的视觉模型的好处。为了培训PALI,我们根据包含100多种语言的10B图像和文本的新图像培训数据集,创建了大量的多语种培训任务组合。PALI在多种视觉和语言任务(如字幕字幕、直观解答、场文解)中达到最新水平(例如可编程、可理解),同时保留一个简单模块、模块、模块、可理解。