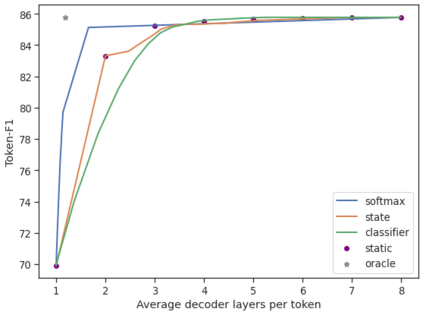
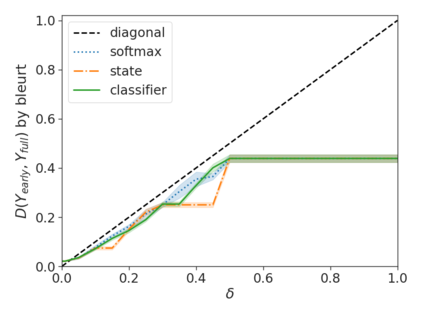
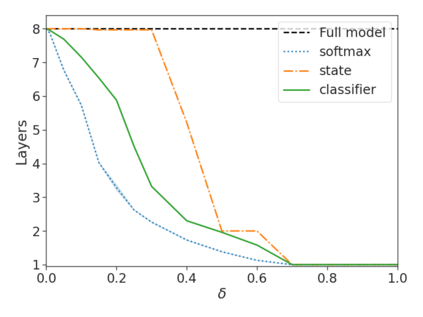
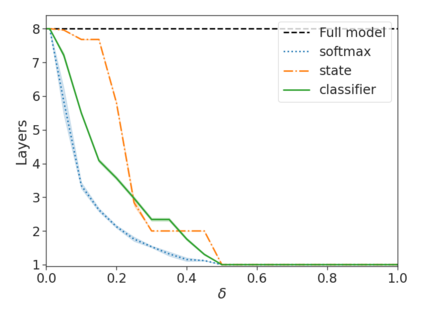
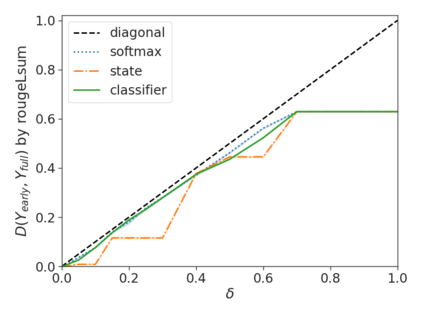
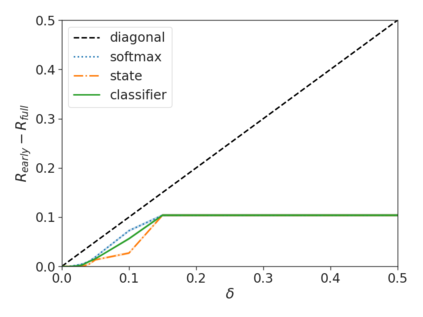
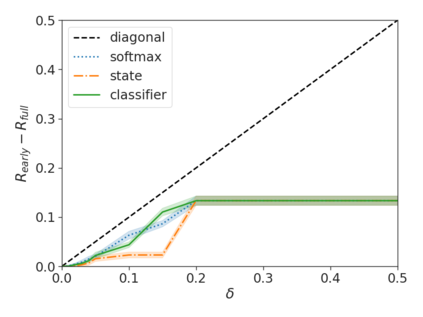
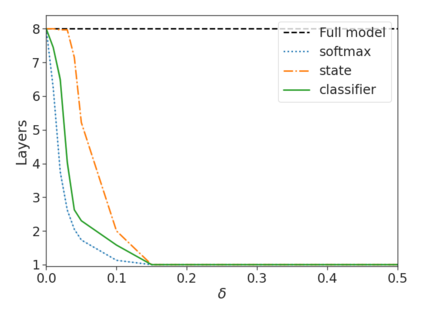
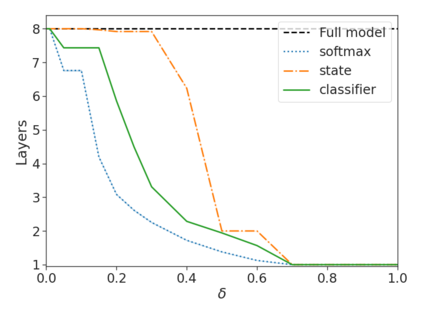
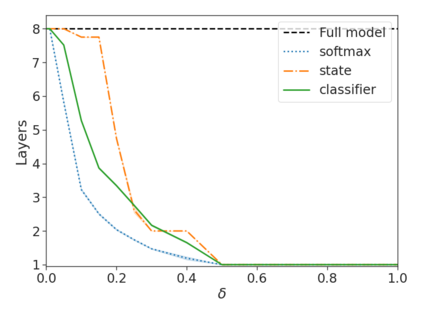
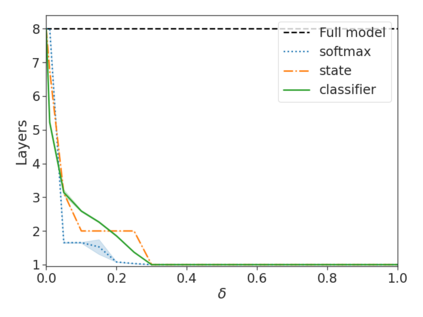
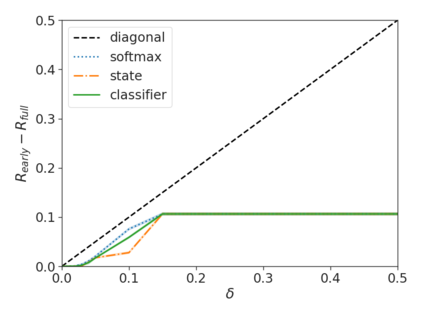
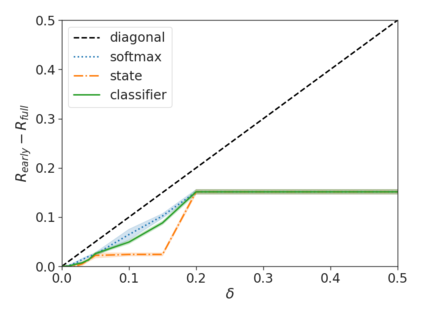
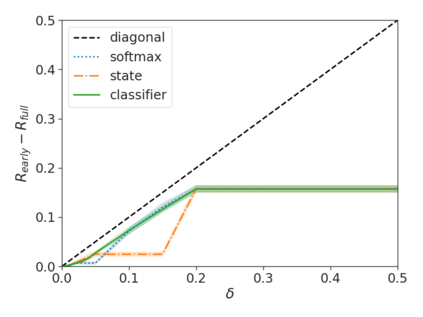
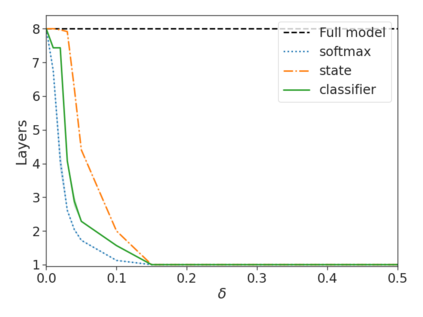
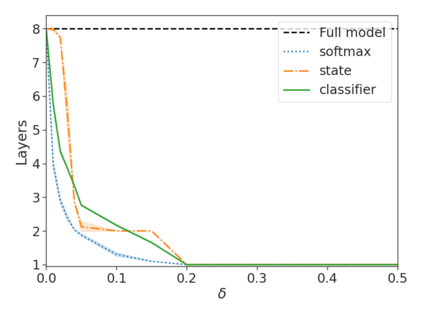
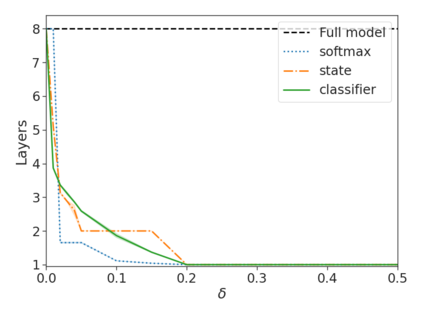
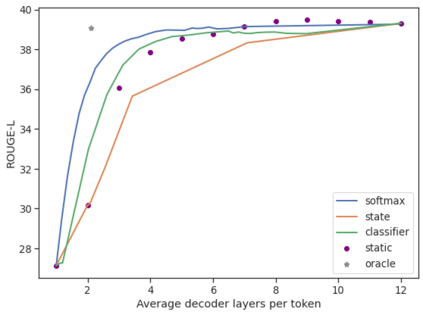
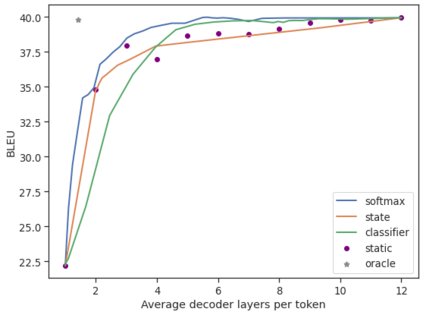
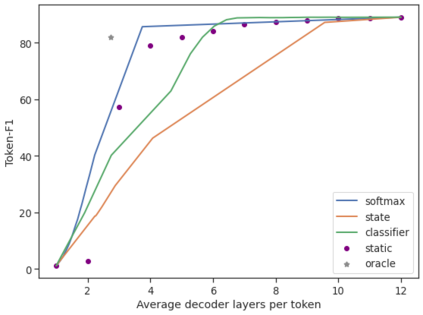
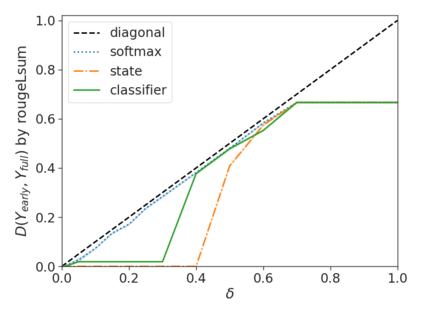
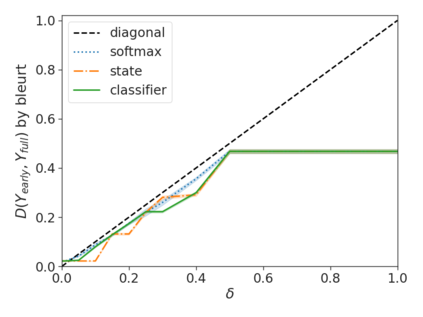
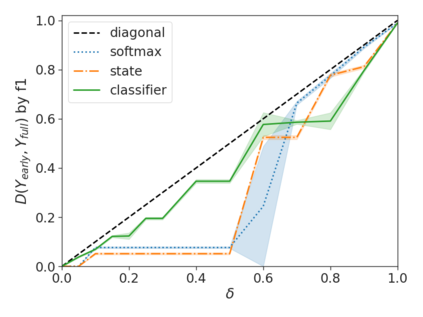
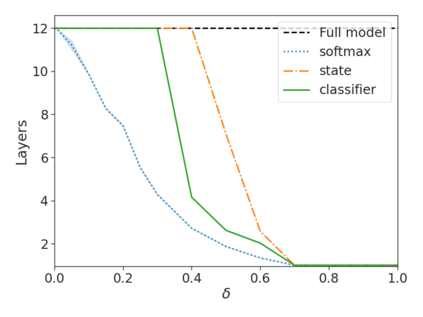
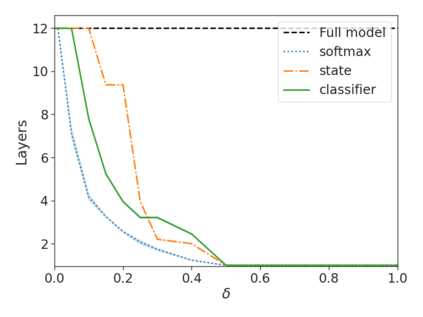
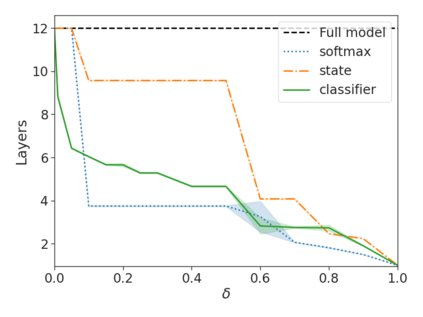
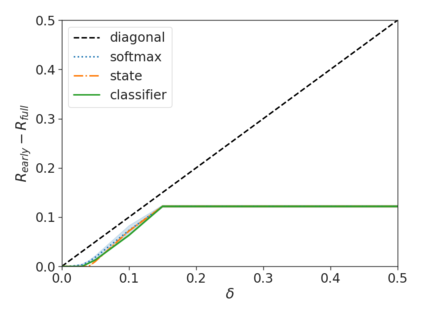
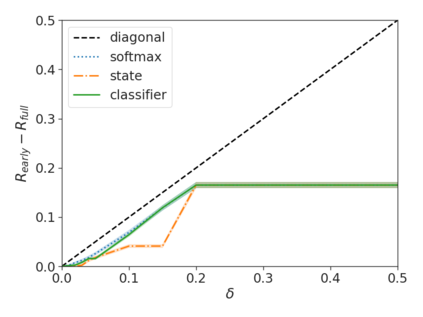
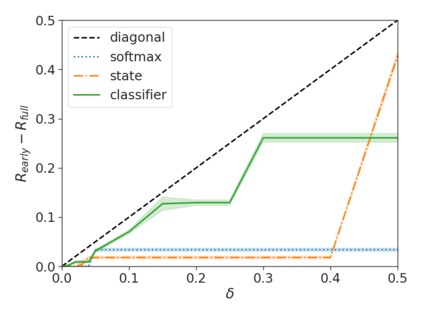
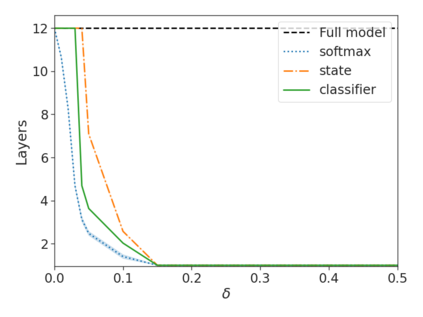
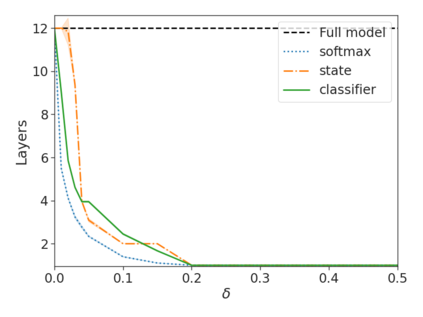
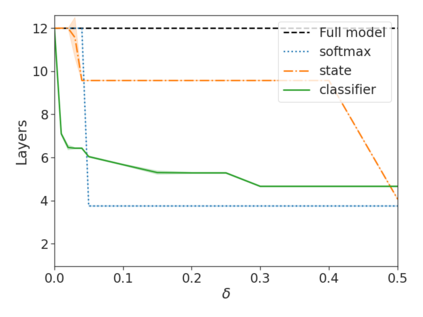
Recent advances in Transformer-based large language models (LLMs) have led to significant performance improvements across many tasks. These gains come with a drastic increase in the models' size, potentially leading to slow and costly use at inference time. In practice, however, the series of generations made by LLMs is composed of varying levels of difficulty. While certain predictions truly benefit from the models' full capacity, other continuations are more trivial and can be solved with reduced compute. In this work, we introduce Confident Adaptive Language Modeling (CALM), a framework for dynamically allocating different amounts of compute per input and generation timestep. Early exit decoding involves several challenges that we address here, such as: (1) what confidence measure to use; (2) connecting sequence-level constraints to local per-token exit decisions; and (3) attending back to missing hidden representations due to early exits in previous tokens. Through theoretical analysis and empirical experiments on three diverse text generation tasks, we demonstrate the efficacy of our framework in reducing compute -- potential speedup of up to $\times 3$ -- while provably maintaining high performance.
翻译:以变异器为基础的大型语言模型(LLMS)最近的进展使许多任务取得了显著的绩效改进。这些成就随着模型规模的大幅扩大而带来显著的绩效改进,可能导致在推论时间使用缓慢和成本高昂。然而,实际上,LLMS的一代人由不同的困难程度组成。虽然某些预测确实受益于模型的全部能力,但其他的延续则更为微不足道,并且可以通过降低计算速度来解决。在这项工作中,我们引入了 " 自信适应语言模型(CALM) " (CALM),这是一个动态分配不同数量计算投入和生成时间间隔的框架。早期退出编码涉及我们在这里讨论的几项挑战,例如:(1) 使用何种信任措施;(2) 将序列级限制与本地的一对一退出决定联系起来;(3) 处理由于先前的早期退出而缺失的隐蔽表述。通过对三种不同文本生成任务的理论分析和实验,我们展示了我们框架在降低计算效率方面的效率 -- 可能加快到3美元的时间 -- 同时保持高性。