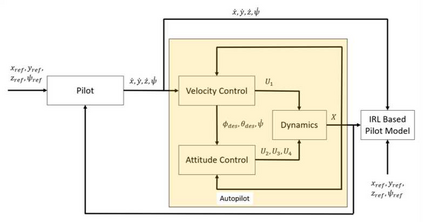
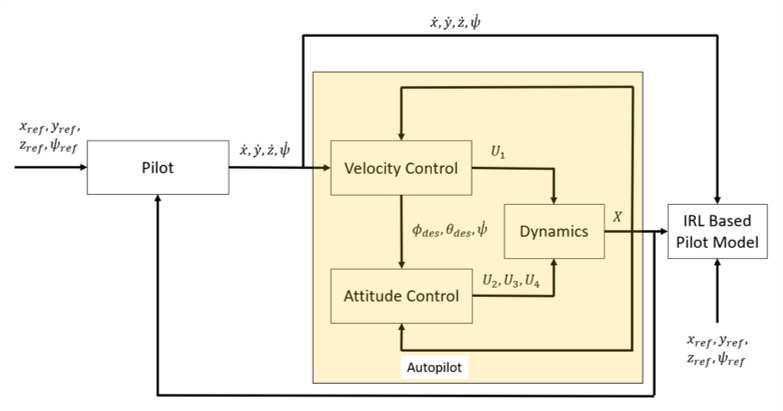
A key challenge in solving the deterministic inverse reinforcement learning problem online and in real time is the existence of non-unique solutions. Nonuniqueness necessitates the study of the notion of equivalent solutions and convergence to such solutions. While \emph{offline} algorithms that result in convergence to equivalent solutions have been developed in the literature, online, real-time techniques that address nonuniqueness are not available. In this paper, a regularized history stack observer is developed to generate solutions that are approximately equivalent. Novel data-richness conditions are developed to facilitate the analysis and simulation results are provided to demonstrate the effectiveness of the developed technique.
翻译:在网上和实时解决决定性的反向强化学习问题的一个关键挑战是是否存在非独特的解决办法。非独一性需要研究等同解决办法的概念和这些解决办法的趋同性。虽然文献中已经开发出导致与等同解决办法趋同的计算法,但没有解决非独一性的在线实时技术。本文开发了正规化的历史堆叠观察器,以产生大致相当的解决办法。开发了新颖的数据丰富性条件,以便利分析和模拟结果,以证明发达技术的有效性。