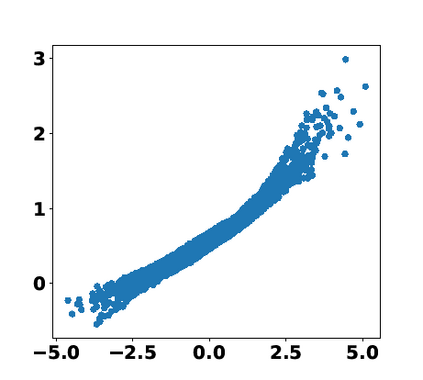
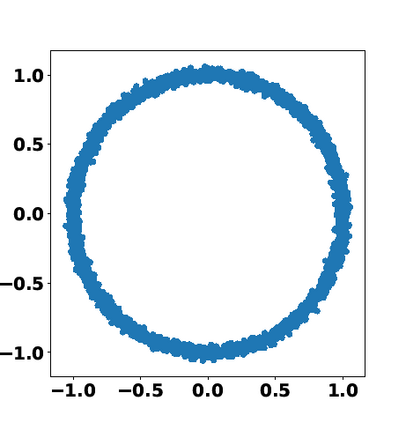
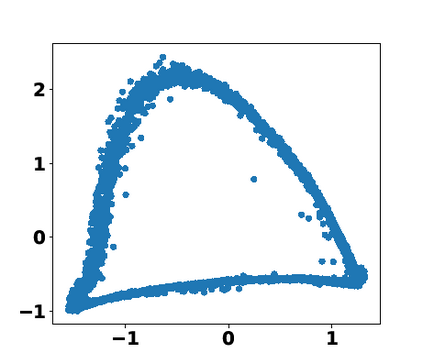
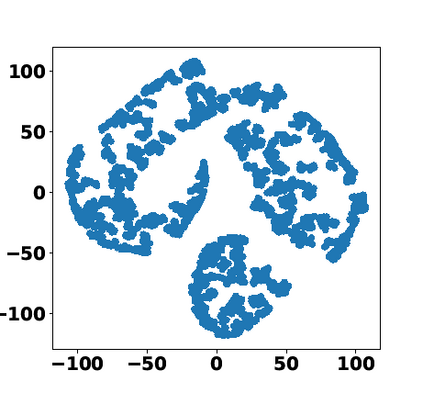
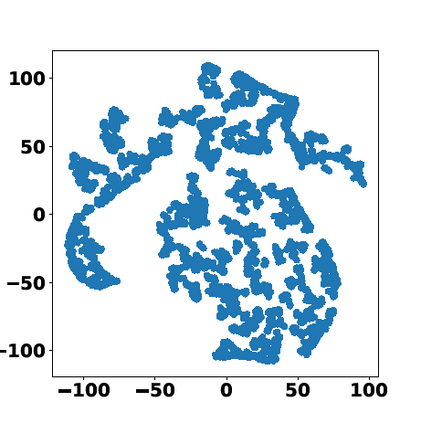
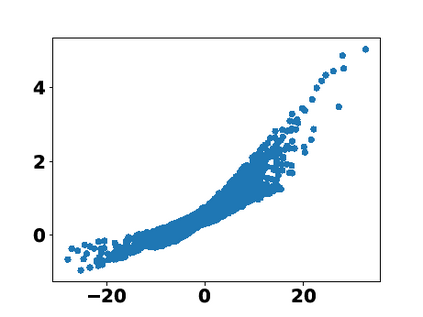
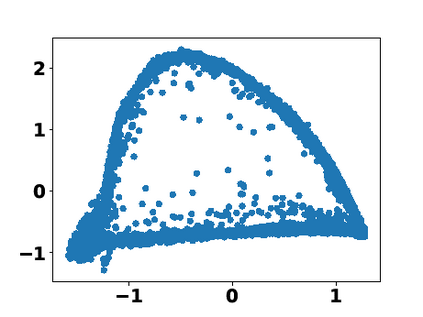
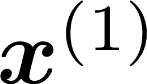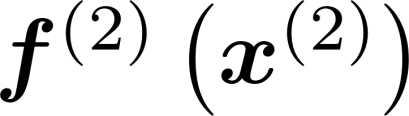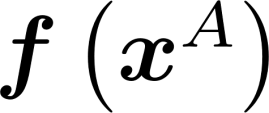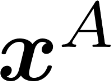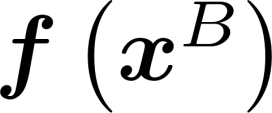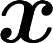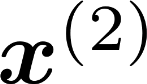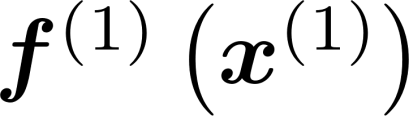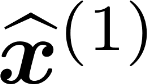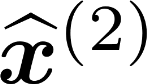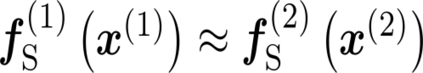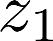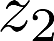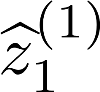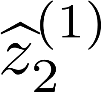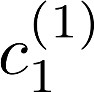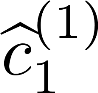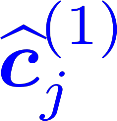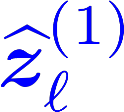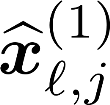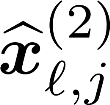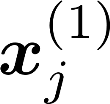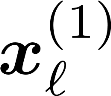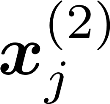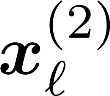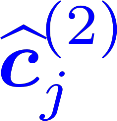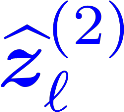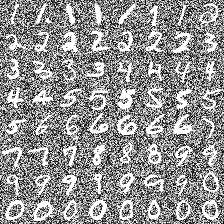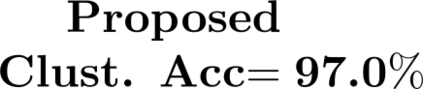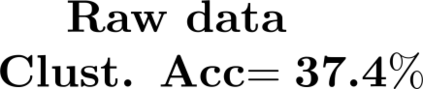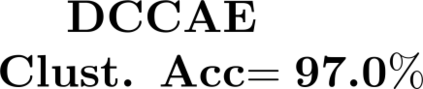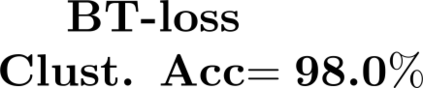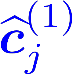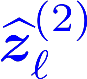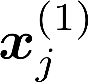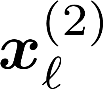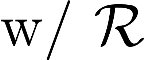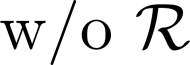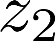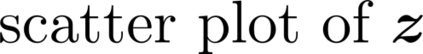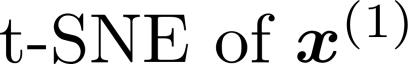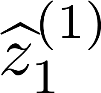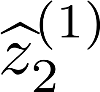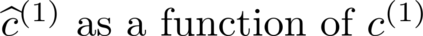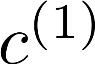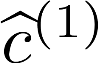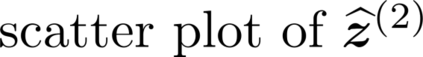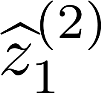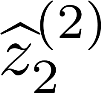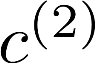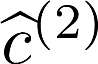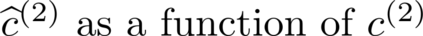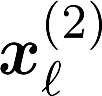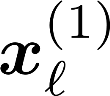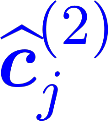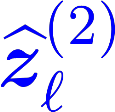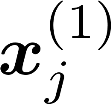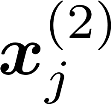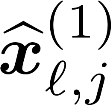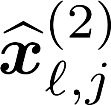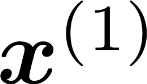Multiple views of data, both naturally acquired (e.g., image and audio) and artificially produced (e.g., via adding different noise to data samples), have proven useful in enhancing representation learning. Natural views are often handled by multiview analysis tools, e.g., (deep) canonical correlation analysis [(D)CCA], while the artificial ones are frequently used in self-supervised learning (SSL) paradigms, e.g., SimCLR and Barlow Twins. Both types of approaches often involve learning neural feature extractors such that the embeddings of data exhibit high cross-view correlations. Although intuitive, the effectiveness of correlation-based neural embedding is only empirically validated. This work puts forth a theory-backed framework for unsupervised multiview learning. Our development starts with proposing a multiview model, where each view is a nonlinear mixture of shared and private components. Consequently, the learning problem boils down to shared/private component identification and disentanglement. Under this model, latent correlation maximization is shown to guarantee the extraction of the shared components across views (up to certain ambiguities). In addition, the private information in each view can be provably disentangled from the shared using proper regularization design. The method is tested on a series of tasks, e.g., downstream clustering, which all show promising performance. Our development also provides a unifying perspective for understanding various DCCA and SSL schemes.
翻译:自然获得(例如图像和音频)和人工制作(例如,通过在数据样本中添加不同噪音)的数据的多重观点,已证明对加强代表性学习有用。自然观点往往由多种观点分析工具处理,例如(深)直肠相关分析[(D)CCA],人为观点经常用于自我监督的学习范式(SSL),例如SimCLR和Barlow Twins。两种方法往往都涉及学习神经特征提取器,例如数据的嵌入显示出高交叉视图的关联性。虽然不直观,但基于关联的神经嵌入的有效性只是经经验验证的。这项工作为不受监督的多视角学习提供了一个理论支持的框架。我们的发展始于提出一种多视角模型,其中每一种观点都是共同和私人组成部分的非线性混合。因此,学习问题归结为共享/私人组成部分的识别和分解。在这个模型下,潜在关联性最大化能够保证利用正常的配置方法对共同的组合进行提取。在正常的排序中,从某种常规化的排序中可以展示共同的排序。