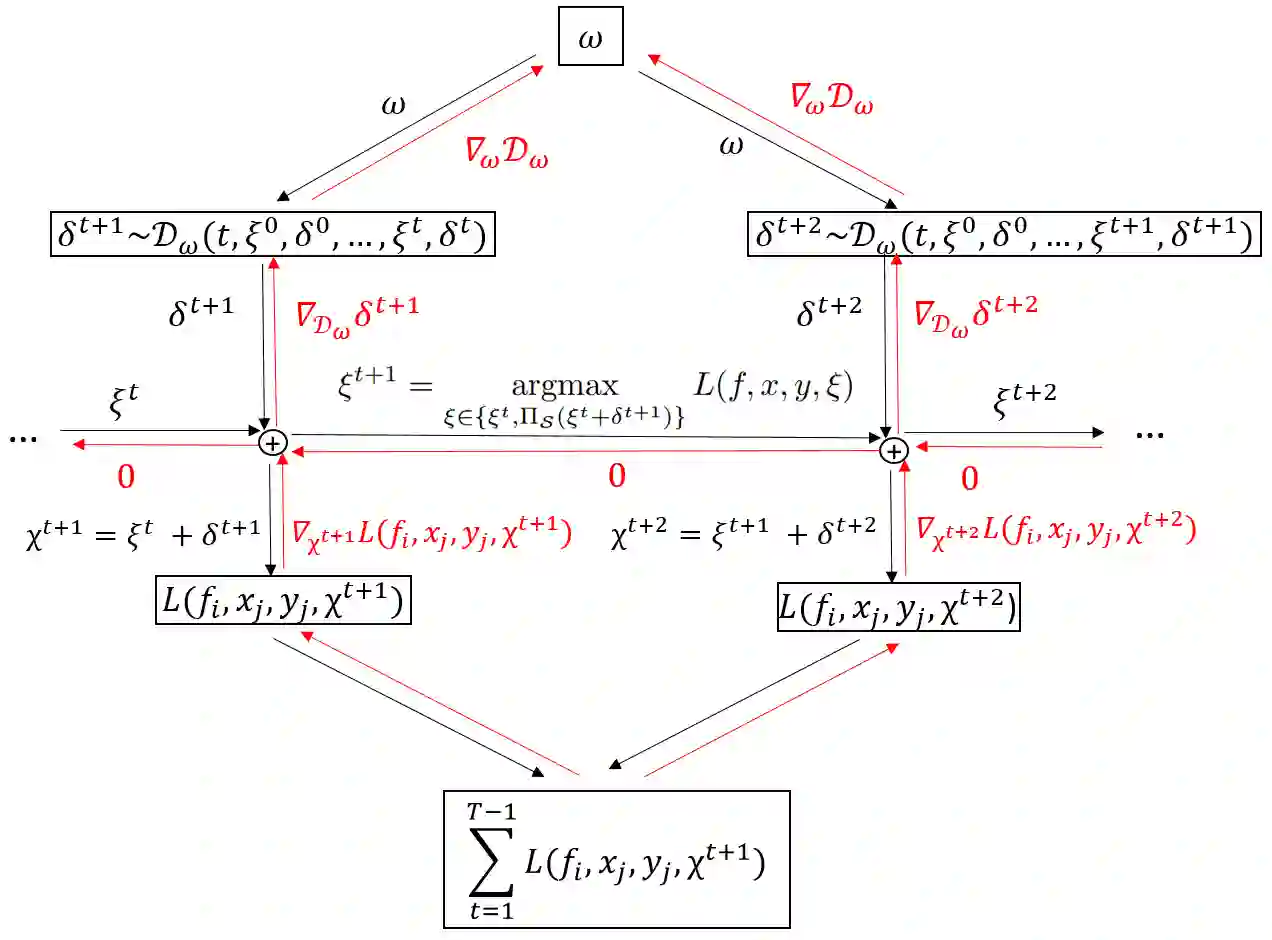
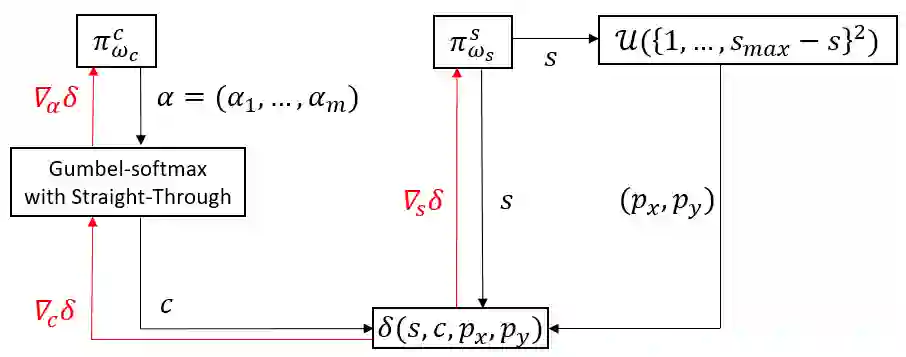
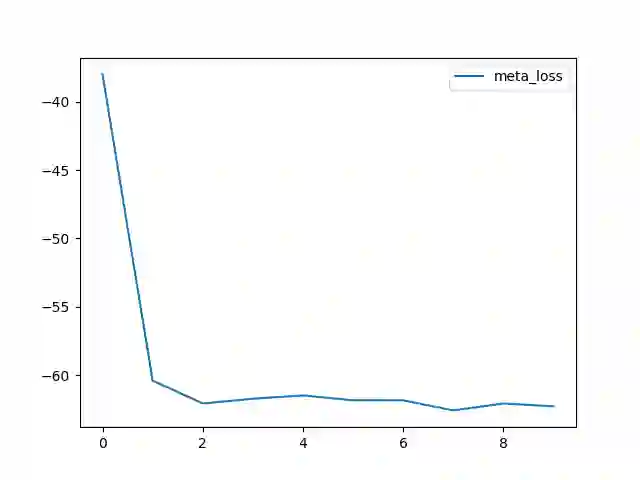
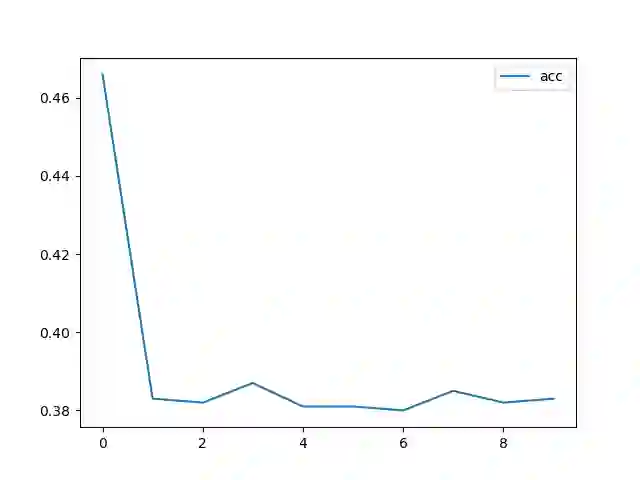
Adversarial attacks based on randomized search schemes have obtained state-of-the-art results in black-box robustness evaluation recently. However, as we demonstrate in this work, their efficiency in different query budget regimes depends on manual design and heuristic tuning of the underlying proposal distributions. We study how this issue can be addressed by adapting the proposal distribution online based on the information obtained during the attack. We consider Square Attack, which is a state-of-the-art score-based black-box attack, and demonstrate how its performance can be improved by a learned controller that adjusts the parameters of the proposal distribution online during the attack. We train the controller using gradient-based end-to-end training on a CIFAR10 model with white box access. We demonstrate that plugging the learned controller into the attack consistently improves its black-box robustness estimate in different query regimes by up to 20% for a wide range of different models with black-box access. We further show that the learned adaptation principle transfers well to the other data distributions such as CIFAR100 or ImageNet and to the targeted attack setting.
翻译:以随机搜索计划为基础的Aversarial攻击最近通过黑盒稳健性评估获得了最新的最新结果。然而,正如我们在这项工作中所显示的那样,不同查询预算制度的效率取决于手动设计和对基本建议分布的过度调整。我们研究如何通过根据攻击期间获得的信息在网上修改提案分发方法解决这一问题。我们考虑Square attack,这是以分数为基础的最先进的黑盒攻击,并表明如何由一个在攻击期间调整在线分配建议书参数的有学控制器改进其性能。我们用基于梯度的终端到终端培训控制器,在使用白箱访问的CIFAR10模型上进行。我们表明,将学习到的控制器插入攻击中,不断提高在不同查询制度中的黑盒稳性估计值,最高达20%,用于使用黑盒访问的范围广泛的不同模型。我们进一步显示,学习到的适应原则向诸如CIFAR100或图像网等其他数据传播方式以及目标攻击设置。