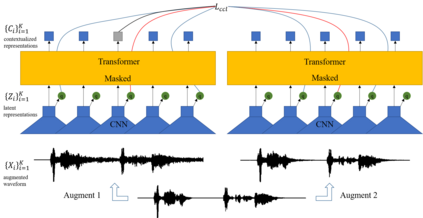
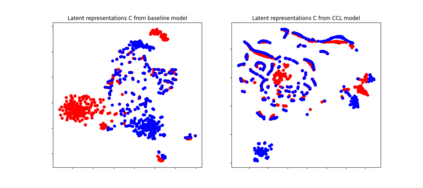
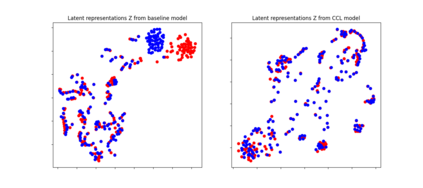
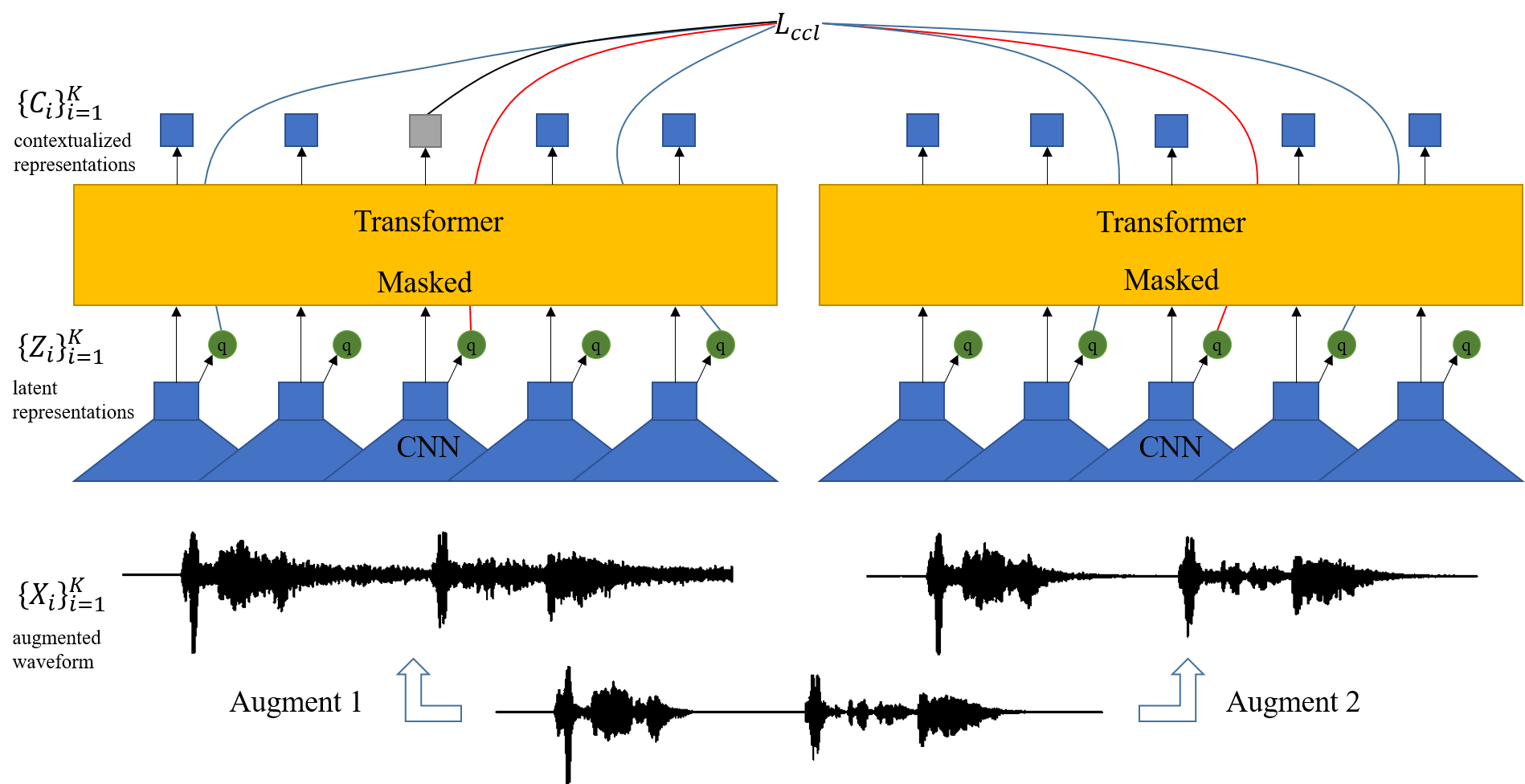
Self-supervised acoustic pre-training has achieved amazing results on the automatic speech recognition (ASR) task. Most of the successful acoustic pre-training methods use contrastive learning to learn the acoustic representations by distinguish the representations from different time steps, ignoring the speaker and environment robustness. As a result, the pre-trained model could show poor performance when meeting out-of-domain data during fine-tuning. In this letter, we design a novel consistency contrastive learning (CCL) method by utilizing data augmentation for acoustic pre-training. Different kinds of augmentation are applied on the original audios and then the augmented audios are fed into an encoder. The encoder should not only contrast the representations within one audio but also maximize the measurement of the representations across different augmented audios. By this way, the pre-trained model can learn a text-related representation method which is more robust with the change of the speaker or the environment.Experiments show that by applying the CCL method on the Wav2Vec2.0, better results can be realized both on the in-domain data and the out-of-domain data. Especially for noisy out-of-domain data, more than 15% relative improvement can be obtained.
翻译:在自动语音识别(ASR)任务上,自我监督的声学预培训在自动语音识别(ASR)任务上取得了惊人的成果。大多数成功的声学预培训方法都采用对比性学习方法,通过区分不同时间步骤来学习声学表达方式,忽略了扬声器和环境的稳健性。因此,在微调过程中,预先培训的模式在满足外部数据时可能表现不佳。在本信中,我们设计了一种新的一致性对比学习方法(CCL),在声学预培训中使用了数据增强功能。在原始音频上应用了不同的增强功能,然后将增强的音频输入到编码器中。编码器不仅应对比一个音频中的表达方式,而且还应最大限度地测量不同扩音频音频的表达方式。这样,预先培训的模式可以学习一种与文本相关的表达方法,该方法与演讲者或环境的改变更加有力。通过在音频前培训前使用CCL方法,在原始音频和扩音频的音频中都应用了不同的增强功能。在原有数据和外部数据中可以取得更好的结果。特别是用于压外位的15度数据。