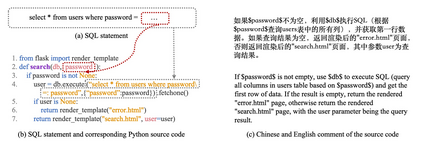
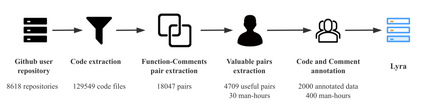
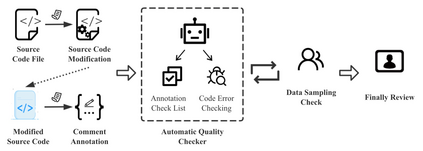
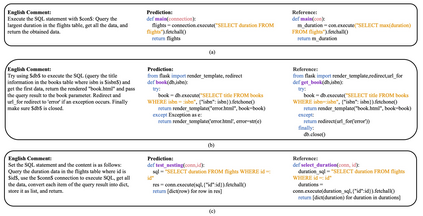
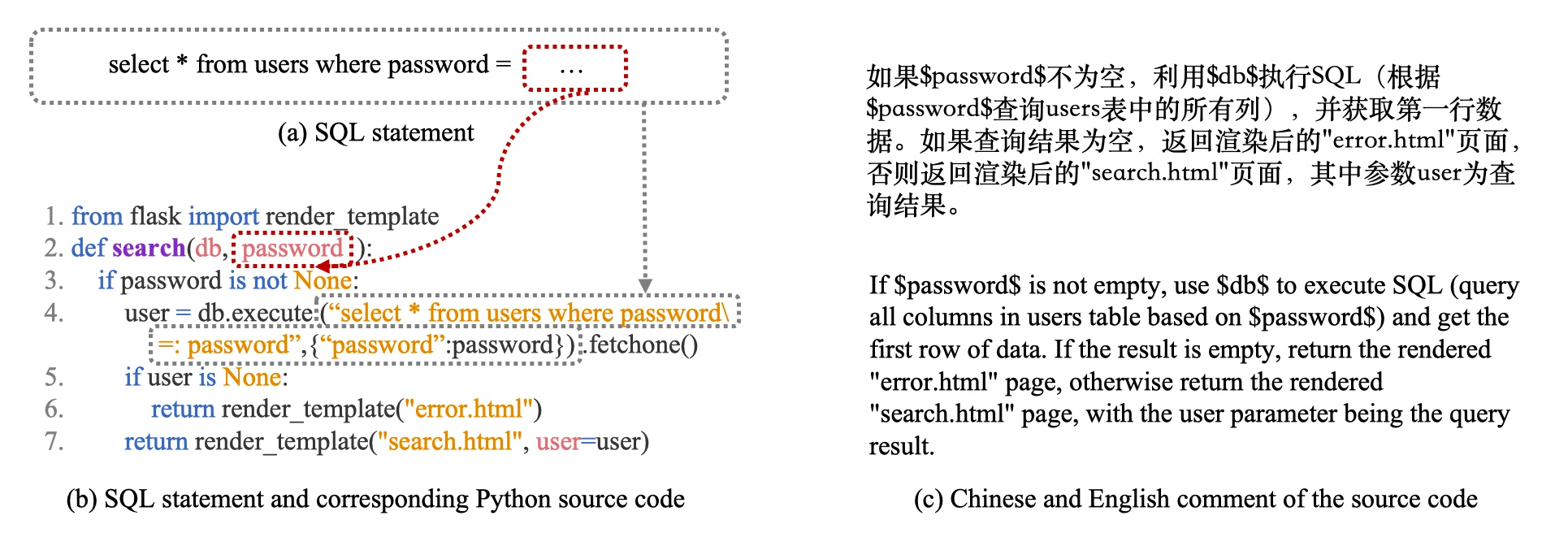
Code generation is crucial to reduce manual software development efforts. Recently, neural techniques have been used to generate source code automatically. While promising, these approaches are evaluated on tasks for generating code in single programming languages. However, in actual development, one programming language is often embedded in another. For example, SQL statements are often embedded as strings in base programming languages such as Python and Java, and JavaScript programs are often embedded in sever-side programming languages, such as PHP, Java, and Python. We call this a turducken-style programming. In this paper, we define a new code generation task: given a natural language comment, this task aims to generate a program in a base language with an embedded language. To our knowledge, this is the first turducken-style code generation task. For this task, we present Lyra: a dataset in Python with embedded SQL. This dataset contains 2,000 carefully annotated database manipulation programs from real usage projects. Each program is paired with both a Chinese comment and an English comment. In our experiment, we adopted Transformer, a state-of-the-art technique, as the baseline. In the best setting, Transformer achieves 0.5% and 1.5% AST exact matching accuracy using Chinese and English comments, respectively. Therefore, we believe that Lyra provides a new challenge for code generation.
翻译:代码生成对于减少人工软件开发努力至关重要 。 最近, 神经技术已被自动地用于生成源代码 。 虽然这些方法很有希望, 但是这些方法在生成单一编程语言代码的任务中得到了评估 。 但是, 在实际开发中, 一种编程语言往往嵌入另一种语言 。 例如, SQL 语句通常作为字符串嵌在基编程语言中, 如 Python 和 Java, 以及 JavaScript 程序通常嵌入于嵌入于嵌入的 Sython 和 JavaScript 等分层编程语言中 。 这个数据集包含2,000 个由实际使用项目( PHP、 Java 和 Python ) 精心加注的数据库操作程序。 我们在本文件中定义了一个新的代码生成任务: 给出自然语言评论, 任务的目的是以嵌入语言生成一个基础语言的程式。 对于我们的知识来说, 这是首个突变式的代码生成任务 。 。 对于这项任务, 我们使用 最精确的版本, 和最精确的 Ry- prefile 。