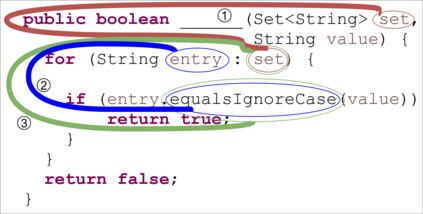
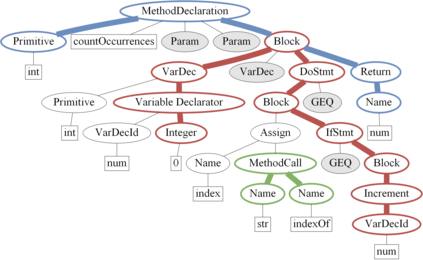
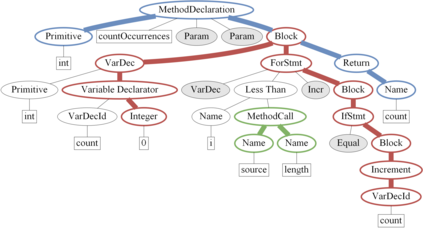
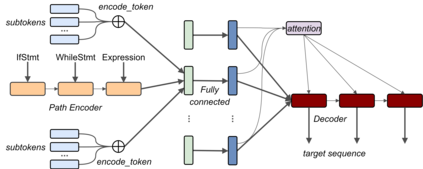
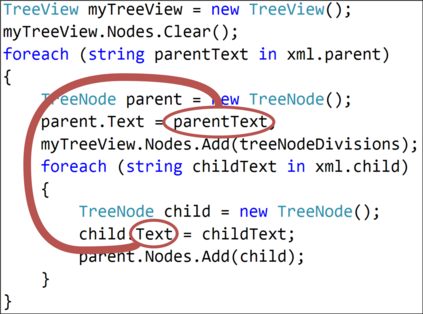
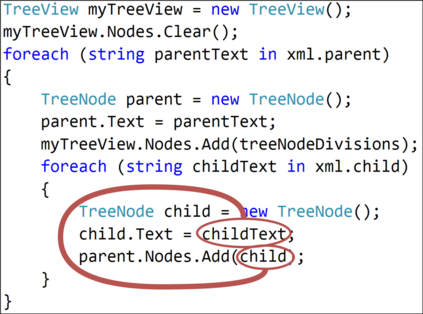
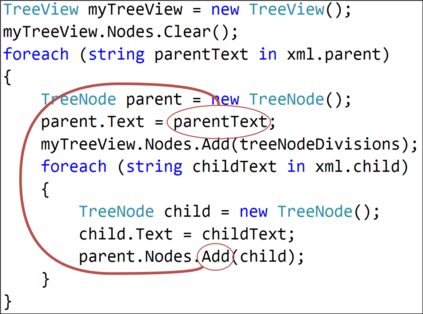
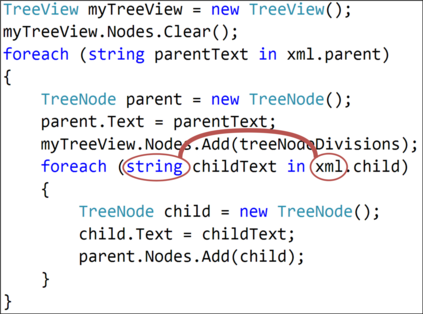
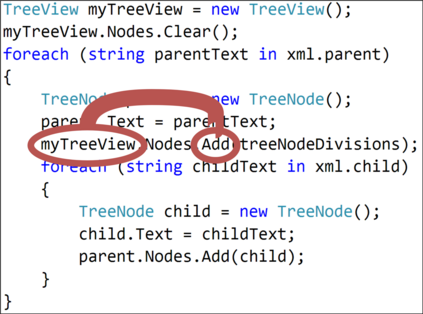
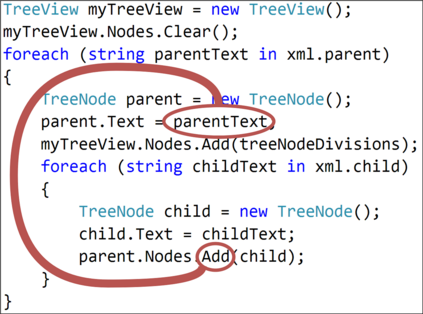
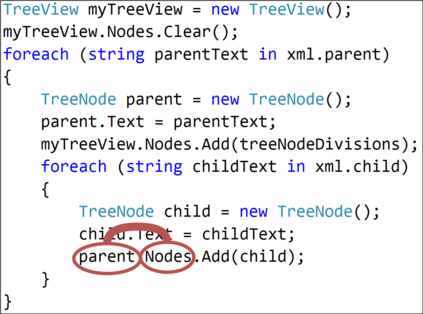
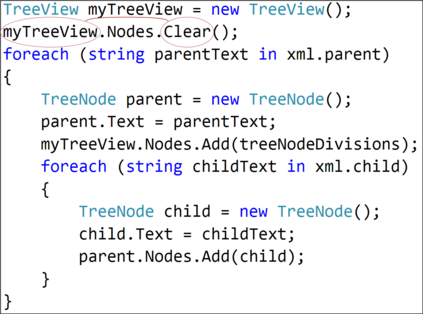
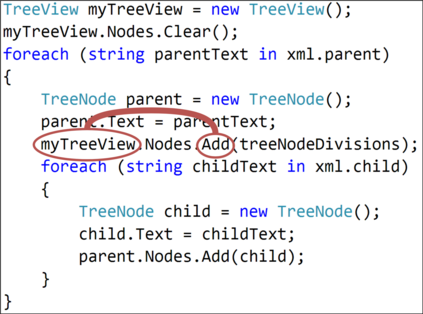
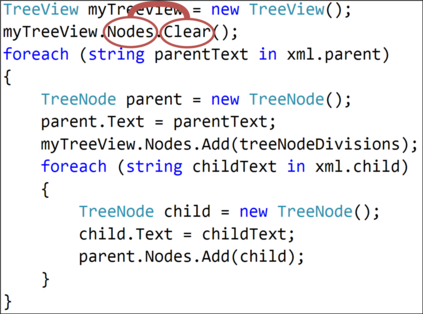
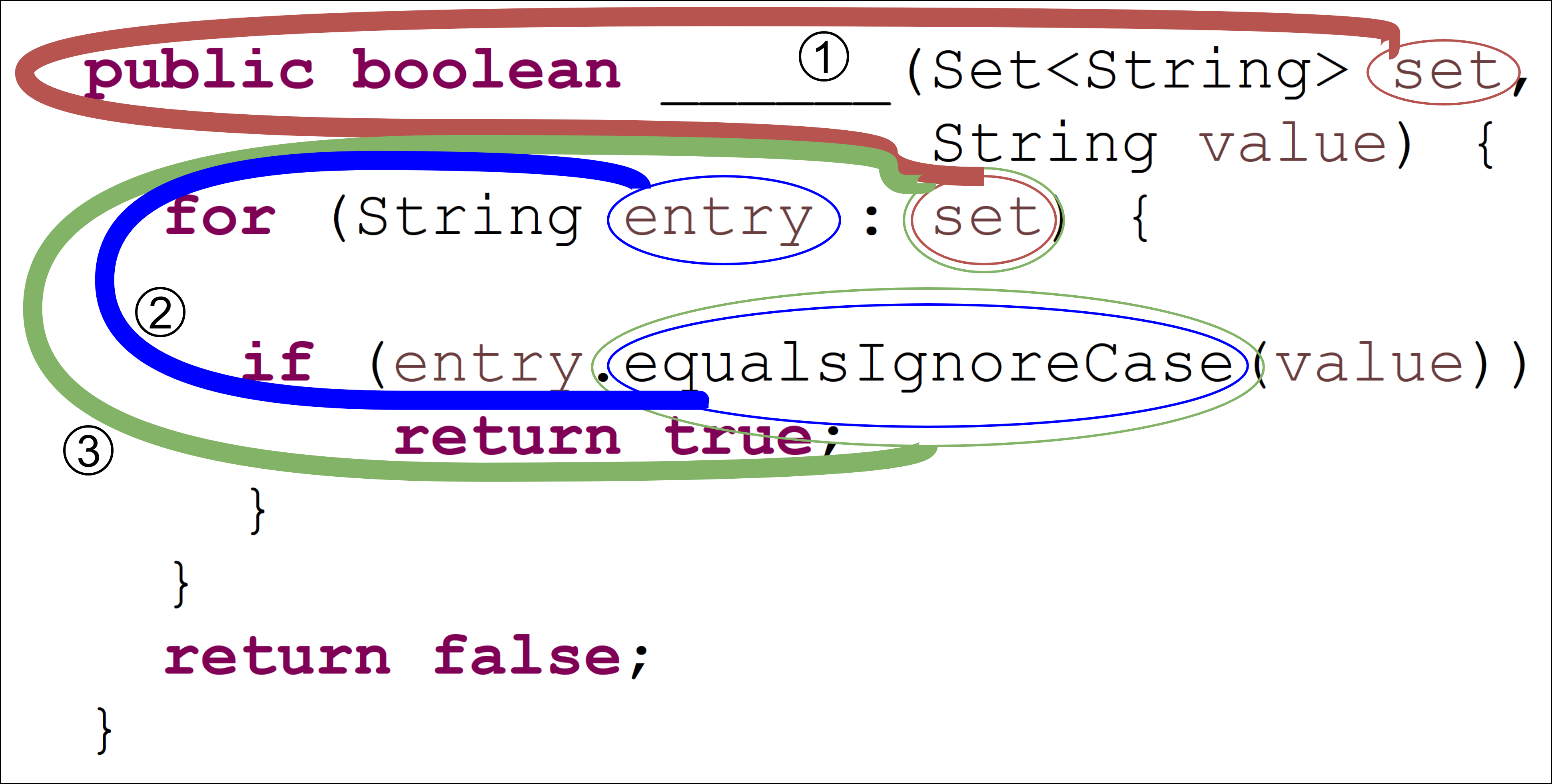
The ability to generate natural language sequences from source code snippets has a variety of applications such as code summarization, documentation, and retrieval. Sequence-to-sequence (seq2seq) models, adopted from neural machine translation (NMT), have achieved state-of-the-art performance on these tasks by treating source code as a sequence of tokens. We present ${\rm {\scriptsize CODE2SEQ}}$: an alternative approach that leverages the syntactic structure of programming languages to better encode source code. Our model represents a code snippet as the set of compositional paths in its abstract syntax tree (AST) and uses attention to select the relevant paths while decoding. We demonstrate the effectiveness of our approach for two tasks, two programming languages, and four datasets of up to $16$M examples. Our model significantly outperforms previous models that were specifically designed for programming languages, as well as state-of-the-art NMT models. An interactive online demo of our model is available at http://code2seq.org. Our code, data and trained models are available at http://github.com/tech-srl/code2seq.
翻译:从源代码片断生成自然语言序列的能力有多种应用,如代码总和、文档和检索等。从神经机器翻译(NMT)中采用的序列到序列(seq2seq)模型,通过将源代码作为象征序列处理,在这些任务上取得了最先进的表现。我们展示了$@rm=Scruitsize CODE2SE ⁇ $:一种利用编程语言合成结构更好地编码源代码的替代方法。我们的模型代表一个代码片段,作为抽象合成图树(AST)中的成份路径集,在解码过程中,利用注意力选择相关路径。我们展示了我们的方法在两种任务(两种程序语言)和四个高达16美元的数据集上的有效性。我们的模型大大超越了以前专门设计用于编程语言的模型,以及NMTMT模式的状态。我们的模型互动在线演示可在http://code2seq.org上查阅。我们的代码、数据和经过培训的模型可在 http://codecodes2-rcodeal/codegred. httpgreabs/teqrcode.