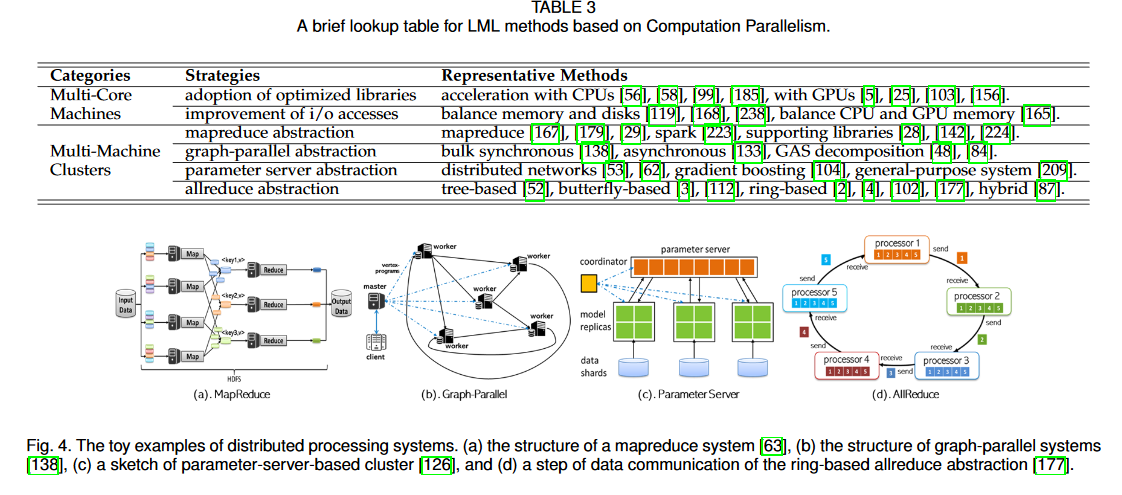
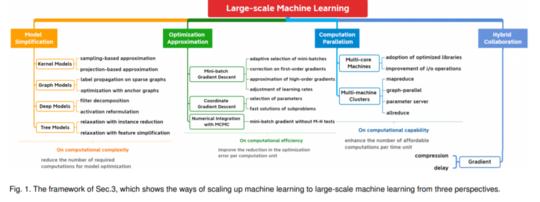
题目
A Survey on Large-scale Machine :大规模机器学习综述
关键词
机器学习,综述调查
摘要
机器学习可以提供对数据的深刻见解,从而使机器能够做出高质量的预测,并已广泛用于诸如文本挖掘,视觉分类和推荐系统之类的实际应用中。 但是,大多数复杂的机器学习方法在处理大规模数据时会耗费大量时间。 这个问题需要大规模机器学习(LML),其目的是从具有可比性能的大数据中学习模式。 在本文中,我们对现有的LML方法进行了系统的调查,为该领域的未来发展提供了蓝图。 我们首先根据提高可伸缩性的方式来划分这些LML方法:1)简化计算复杂度的模型,2)优化计算效率的近似值,以及3)提高计算的并行性。 然后,根据目标场景对每种方法进行分类,并根据内在策略介绍代表性方法。最后,我们分析其局限性并讨论潜在的方向以及未来有望解决的开放问题。
简介
机器学习使机器能够从数据中学习模式,从而无需手动发现和编码模式。 尽管如此,相对于训练实例或模型参数的数量,许多有效的机器学习方法都面临二次时间复杂性[70]。 近年来,随着数据规模的迅速增长[207],这些机器学习方法变得不堪重负,难以为现实应用服务。 为了开发大数据的金矿,因此提出了大规模机器学习(LML)。 它旨在解决可用计算资源上的常规机器学习任务,特别着重于处理大规模数据。 LML可以以几乎线性(甚至更低)的时间复杂度处理任务,同时获得可比的精度。 因此,它已成为可操作的见解的大数据分析的核心。 例如,Waymo和Tesla Autopilot等自动驾驶汽车在计算机视觉中应用了卷积网络,以实时图像感知周围环境[115]; 诸如Netflix和Amazon之类的在线媒体和电子商务站点从用户历史到产品推荐都建立了有效的协作过滤模型[18]。总而言之,LML在我们的日常生活中一直扮演着至关重要的和不可或缺的角色。
鉴于对从大数据中学习的需求不断增长,对此领域的系统调查变得非常科学和实用。 尽管在大数据分析领域已经发表了一些调查报告[12],[33],[54],[193],但它们在以下方面还不够全面。 首先,它们大多数只专注于LML的一个观点,而忽略了互补性。它限制了它们在该领域的价值,并无法促进未来的发展。例如,[12]专注于预测模型而没有发现优化问题,[33]在忽略并行化的同时回顾了随机优化算法,[193]仅关注了 大数据处理系统,并讨论系统支持的机器学习方法。 其次,大多数调查要么失去对所审查方法的洞察力,要么忽视了最新的高质量文献。 例如,[12]缺乏讨论模型的计算复杂性的讨论,[33]忽略了处理高维数据的优化算法,[120]将其研究限于Hadoop生态系统中的分布式数据分析。 从计算角度回顾了200多篇Paperson LML,并进行了更深入的分析,并讨论了未来的研究方向。 我们为从业者提供查找表,以根据他们的需求和资源选择预测模型,优化算法和处理系统。 此外,我们为研究人员提供了有关当前策略的见解,以更有效地开发下一代LML的指南。
我们将贡献总结如下。 首先,我们根据三个计算角度对LML进行了全面概述。 具体来说,它包括:1)模型简化,通过简化预测模型来降低计算复杂性; 2)优化近似,通过设计更好的优化算法来提高计算效率; 3)计算并行性,通过调度多个计算设备来提高计算能力。其次,我们对现有的LML方法进行了深入的分析。 为此,我们根据目标场景将每个角度的方法划分为更精细的类别。 我们分析了它们促进机器学习过程的动机和内在策略。 然后,我们介绍了具有代表性的成就的特征。此外,我们还回顾了混合方法,这些方法共同改善了协同效应的多个视角。 第三,我们从各个角度分析了LML方法的局限性,并根据其扩展提出了潜在的发展方向。 此外,我们讨论了有关LML未来发展的一些相关问题。
本文的结构如下。 我们首先在第2节中介绍了机器学习的一般框架,然后对其有效性和效率进行了高层次的讨论。在第3节中,我们全面回顾了最新的LML方法并深入了解了它们的好处和优势。 局限性。 最后,在第5节结束本文之前,我们讨论了解决第4节中的局限性和其他有希望的未解决问题的未来方向。