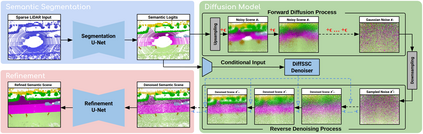
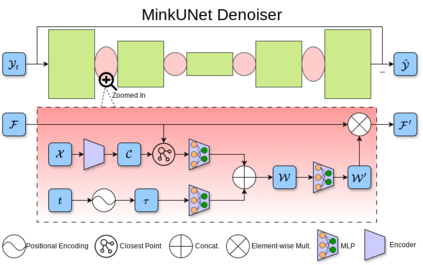
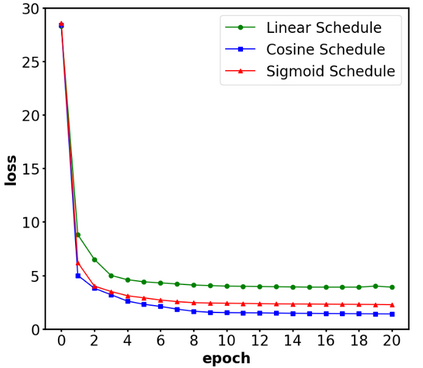
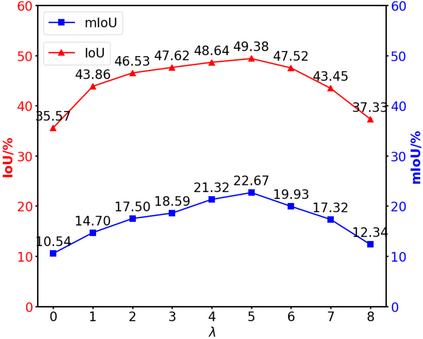
Perception systems play a crucial role in autonomous driving, incorporating multiple sensors and corresponding computer vision algorithms. 3D LiDAR sensors are widely used to capture sparse point clouds of the vehicle's surroundings. However, such systems struggle to perceive occluded areas and gaps in the scene due to the sparsity of these point clouds and their lack of semantics. To address these challenges, Semantic Scene Completion (SSC) jointly predicts unobserved geometry and semantics in the scene given raw LiDAR measurements, aiming for a more complete scene representation. Building on promising results of diffusion models in image generation and super-resolution tasks, we propose their extension to SSC by implementing the noising and denoising diffusion processes in the point and semantic spaces individually. To control the generation, we employ semantic LiDAR point clouds as conditional input and design local and global regularization losses to stabilize the denoising process. We evaluate our approach on autonomous driving datasets and our approach outperforms the state-of-the-art for SSC.
翻译:暂无翻译