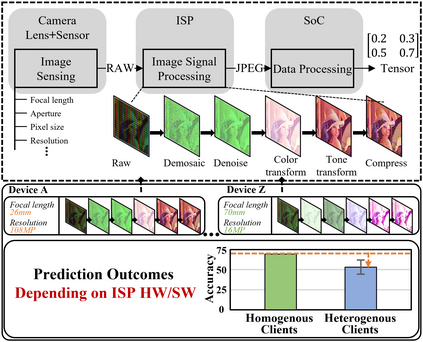
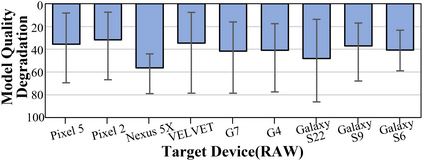
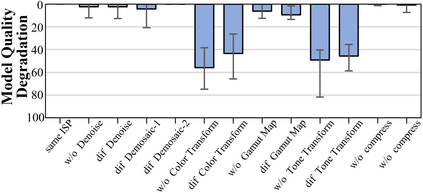
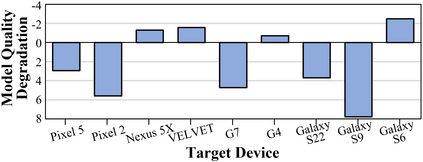
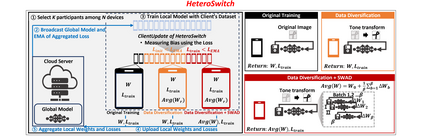
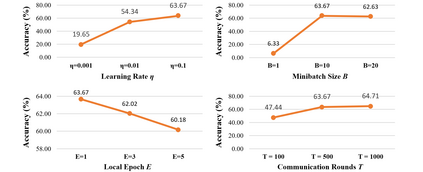
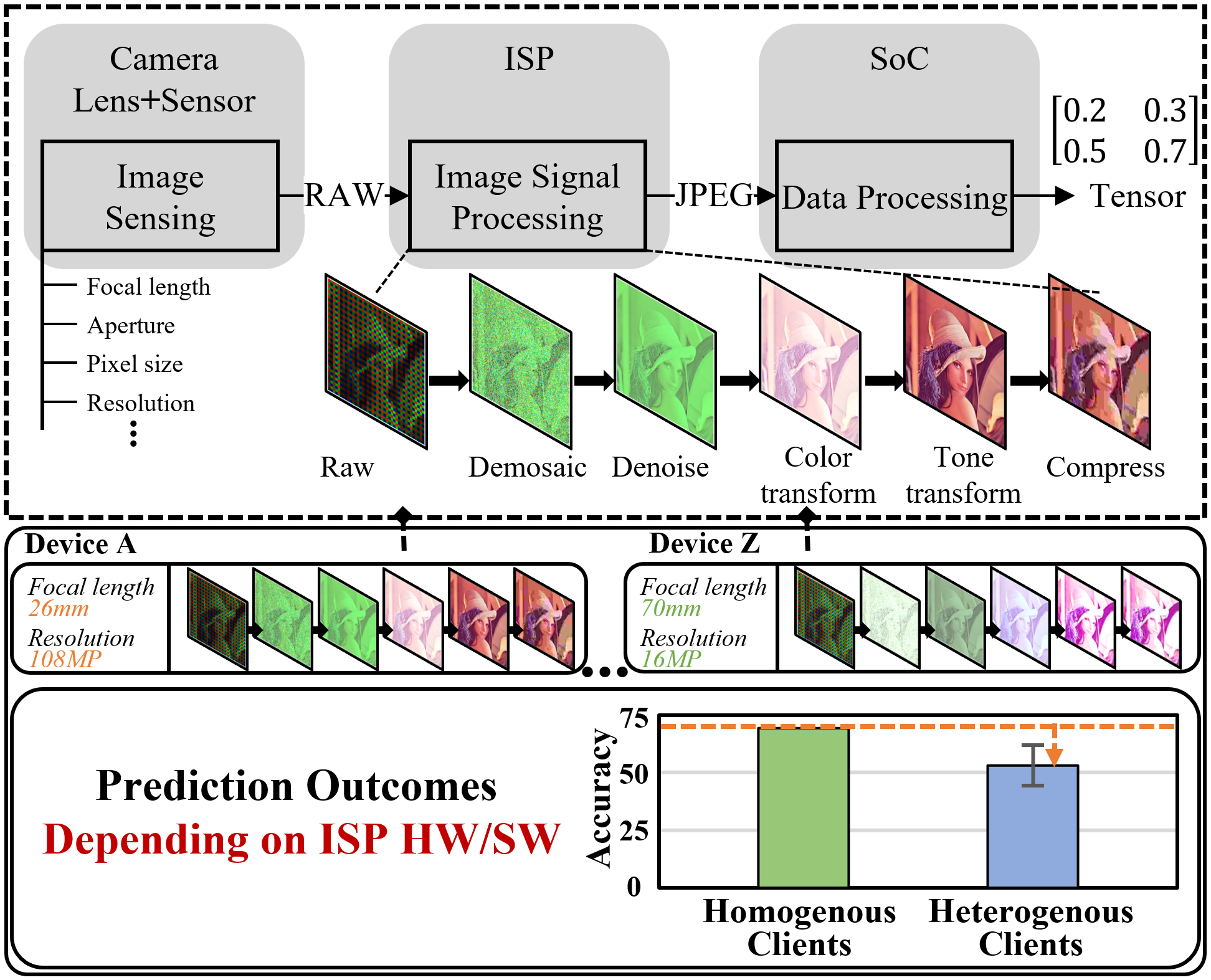
Federated Learning (FL) is a practical approach to train deep learning models collaboratively across user-end devices, protecting user privacy by retaining raw data on-device. In FL, participating user-end devices are highly fragmented in terms of hardware and software configurations. Such fragmentation introduces a new type of data heterogeneity in FL, namely \textit{system-induced data heterogeneity}, as each device generates distinct data depending on its hardware and software configurations. In this paper, we first characterize the impact of system-induced data heterogeneity on FL model performance. We collect a dataset using heterogeneous devices with variations across vendors and performance tiers. By using this dataset, we demonstrate that \textit{system-induced data heterogeneity} negatively impacts accuracy, and deteriorates fairness and domain generalization problems in FL. To address these challenges, we propose HeteroSwitch, which adaptively adopts generalization techniques (i.e., ISP transformation and SWAD) depending on the level of bias caused by varying HW and SW configurations. In our evaluation with a realistic FL dataset (FLAIR), HeteroSwitch reduces the variance of averaged precision by 6.3\% across device types.
翻译:暂无翻译