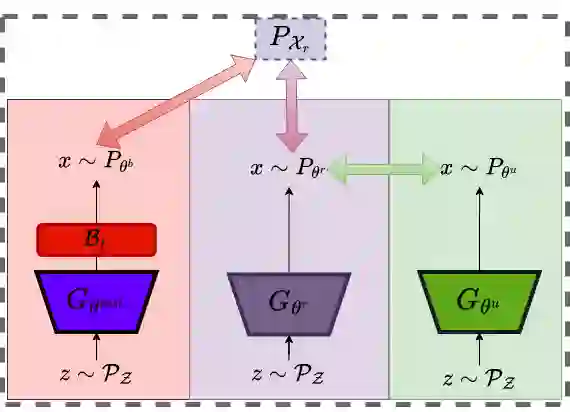
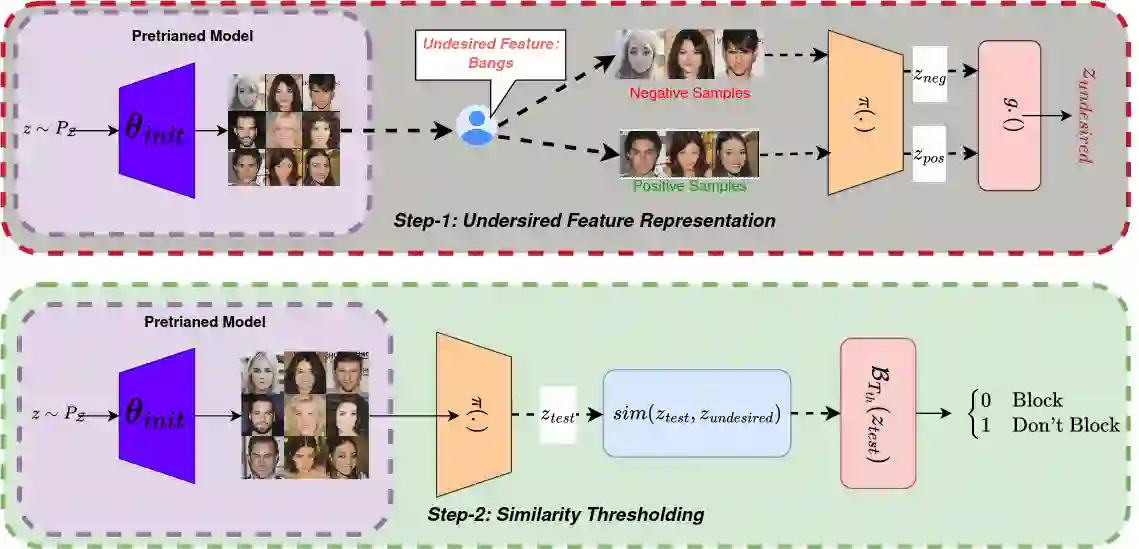
The heightened emphasis on the regulation of deep generative models, propelled by escalating concerns pertaining to privacy and compliance with regulatory frameworks, underscores the imperative need for precise control mechanisms over these models. This urgency is particularly underscored by instances in which generative models generate outputs that encompass objectionable, offensive, or potentially injurious content. In response, machine unlearning has emerged to selectively forget specific knowledge or remove the influence of undesirable data subsets from pre-trained models. However, modern machine unlearning approaches typically assume access to model parameters and architectural details during unlearning, which is not always feasible. In multitude of downstream tasks, these models function as black-box systems, with inaccessible pre-trained parameters, architectures, and training data. In such scenarios, the possibility of filtering undesired outputs becomes a practical alternative. The primary goal of this study is twofold: first, to elucidate the relationship between filtering and unlearning processes, and second, to formulate a methodology aimed at mitigating the display of undesirable outputs generated from models characterized as black-box systems. Theoretical analysis in this study demonstrates that, in the context of black-box models, filtering can be seen as a form of weak unlearning. Our proposed \textbf{\textit{Feature Aware Similarity Thresholding(FAST)}} method effectively suppresses undesired outputs by systematically encoding the representation of unwanted features in the latent space.
翻译:暂无翻译