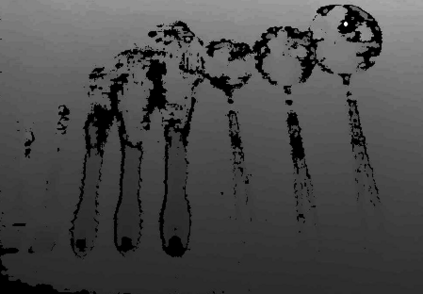
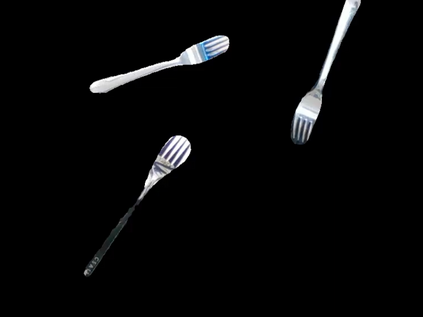
Thin, reflective objects such as forks and whisks are common in our daily lives, but they are particularly challenging for robot perception because it is hard to reconstruct them using commodity RGB-D cameras or multi-view stereo techniques. While traditional pipelines struggle with objects like these, Neural Radiance Fields (NeRFs) have recently been shown to be remarkably effective for performing view synthesis on objects with thin structures or reflective materials. In this paper we explore the use of NeRF as a new source of supervision for robust robot vision systems. In particular, we demonstrate that a NeRF representation of a scene can be used to train dense object descriptors. We use an optimized NeRF to extract dense correspondences between multiple views of an object, and then use these correspondences as training data for learning a view-invariant representation of the object. NeRF's usage of a density field allows us to reformulate the correspondence problem with a novel distribution-of-depths formulation, as opposed to the conventional approach of using a depth map. Dense correspondence models supervised with our method significantly outperform off-the-shelf learned descriptors by 106% (PCK@3px metric, more than doubling performance) and outperform our baseline supervised with multi-view stereo by 29%. Furthermore, we demonstrate the learned dense descriptors enable robots to perform accurate 6-degree of freedom (6-DoF) pick and place of thin and reflective objects.
翻译:虽然传统管道与像RGB-D摄像头或多视图立体技术这样的物体发生争斗,但最近显示,神经辐射场(NERFs)在对薄结构或反射材料的物体进行视觉合成方面非常有效。在本文中,我们探索使用NERF作为稳健机器人视觉系统的新监督来源。特别是,我们证明,可以使用NERF的场景代表方式来训练密度浓厚的物体描述器。我们使用优化的NERF来提取多个对象视图之间的密集对应,然后将这些通信作为培训数据,学习该物体的视觉变化性表示法。NERF对密度场的利用使得我们能够用新颖的深度分布制来重新描述对应问题,而不是使用常规的深度映射法。我们所监督的NERF对场面代表的强烈通信模型可以大大超越精密的物体描述器描述器。我们使用最精密的直直径比直径直的直径直径直径直径直径直径直径直的图像模型,我们用10 %的直径直径直径直径直径直的图像比我们所学的直径直径直径直径直径直径直的平方的平方的平面演示,再演示。