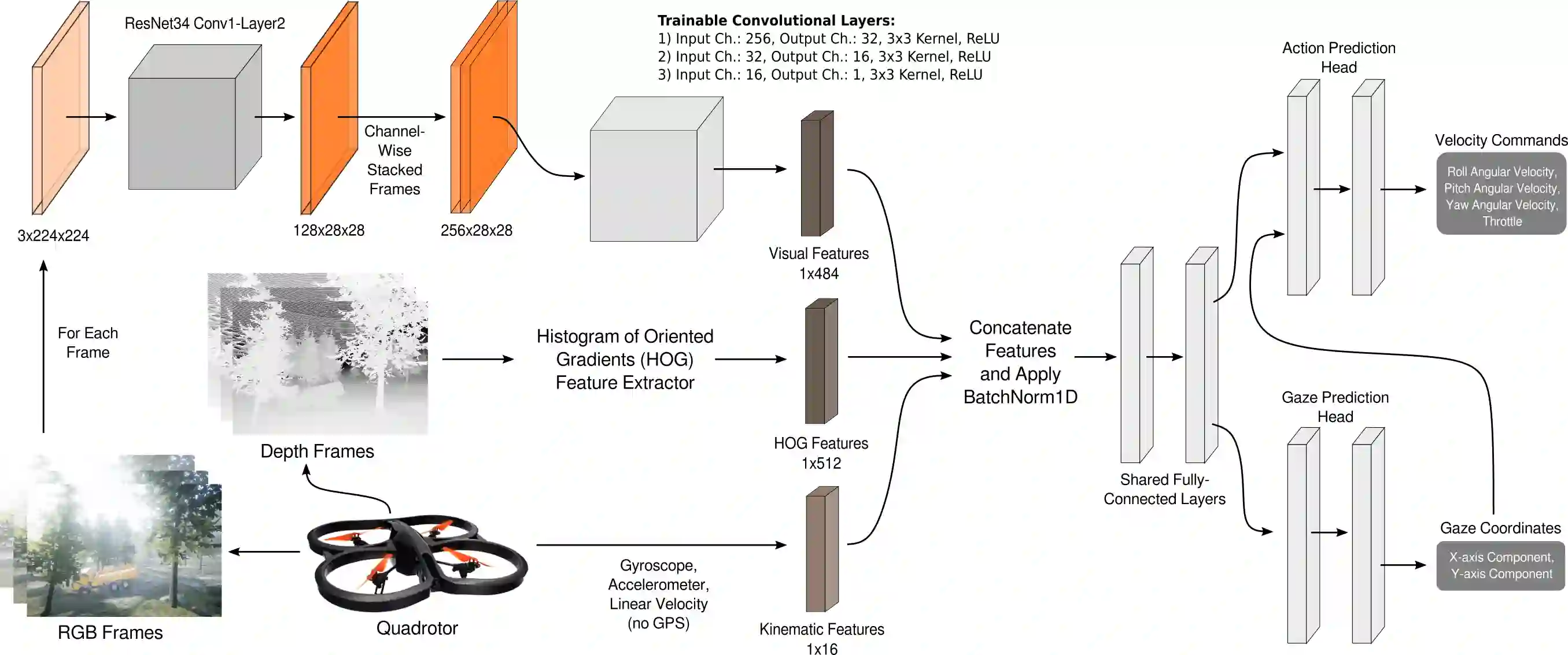
In the field of human-robot interaction, teaching learning agents from human demonstrations via supervised learning has been widely studied and successfully applied to multiple domains such as self-driving cars and robot manipulation. However, the majority of the work on learning from human demonstrations utilizes only behavioral information from the demonstrator, i.e. what actions were taken, and ignores other useful information. In particular, eye gaze information can give valuable insight towards where the demonstrator is allocating their visual attention, and leveraging such information has the potential to improve agent performance. Previous approaches have only studied the utilization of attention in simple, synchronous environments, limiting their applicability to real-world domains. This work proposes a novel imitation learning architecture to learn concurrently from human action demonstration and eye tracking data to solve tasks where human gaze information provides important context. The proposed method is applied to a visual navigation task, in which an unmanned quadrotor is trained to search for and navigate to a target vehicle in a real-world, photorealistic simulated environment. When compared to a baseline imitation learning architecture, results show that the proposed gaze augmented imitation learning model is able to learn policies that achieve significantly higher task completion rates, with more efficient paths, while simultaneously learning to predict human visual attention. This research aims to highlight the importance of multimodal learning of visual attention information from additional human input modalities and encourages the community to adopt them when training agents from human demonstrations to perform visuomotor tasks.
翻译:在人-机器人互动领域,通过监督学习进行人类示范的教学人员通过人文演示的教学代理已经广泛研究,并成功地应用于诸如自行驾驶汽车和机器人操纵等多个领域;然而,从人类示范学习的大部分工作仅利用演示人的行为信息,即已采取的行动,而忽略了其他有用的信息;特别是,眼视信息可以提供宝贵的洞察力,了解演示人视觉关注的地点,利用这种信息有可能改善代理人的性能。以前的做法仅研究在简单、同步环境中利用注意力的情况,限制其适用于现实世界域。这项工作提出了一种新型仿真学习结构,从人类行动演示中学习,同时用眼睛跟踪数据,解决人类视觉信息提供重要背景的任务。拟议方法用于视觉导航任务,在视觉导航任务中训练无人驾驶的夸德罗托尔在现实世界中搜索和导航目标飞行器,模拟光真知灼见地模拟环境。与基线模拟学习结构相比,结果显示拟议的视觉学习模型从增强模仿学习模式到对现实域域域域的适用性。在学习高视觉任务完成率的同时,可以学习更多了解人类研究方式,同时学习人文研究方法,同时学习人文研究方法,同时学习人文研究方法,从而学习人文研究方式学习人文的进度,学习更多的研究,从而了解人类视觉研究,从而了解人类的进度,同时学习人文研究方法,从而学习了人类任务完成率。