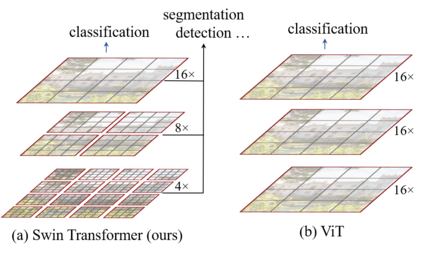
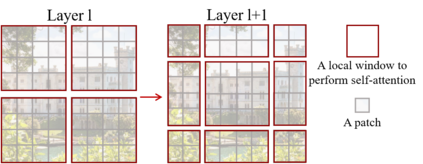
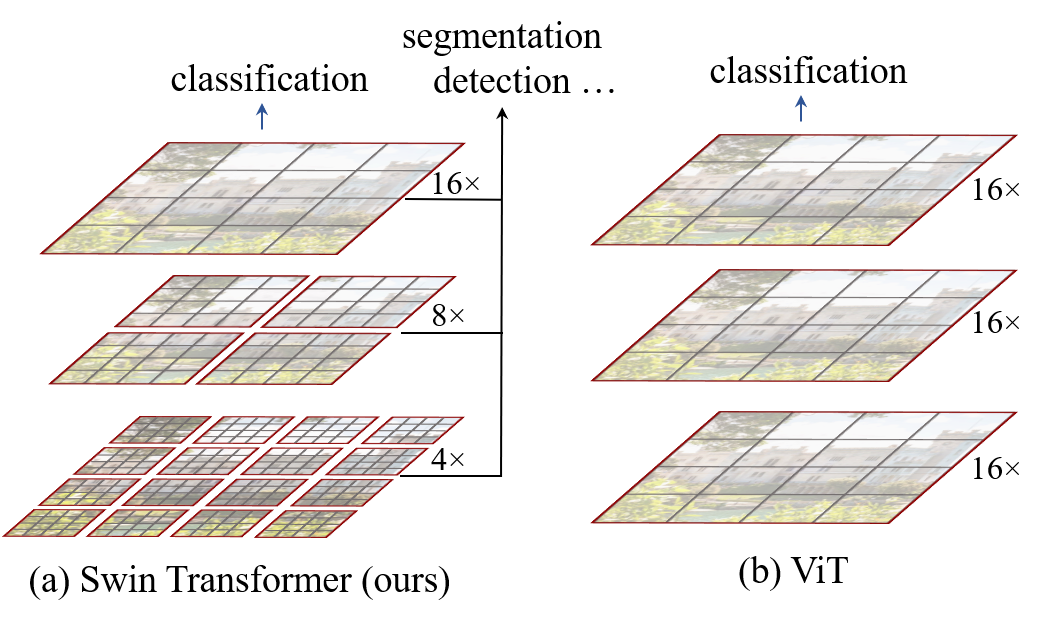
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (86.4 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The code and models will be made publicly available at~\url{https://github.com/microsoft/Swin-Transformer}.
翻译:本文展示了一个新的视觉变换器,名为 Swin 变换器,这个变换器可以作为计算机变换器的通用主干线。 变换器从语言到视觉的挑战来自两个领域之间的差异, 例如视觉实体的规模差异很大,图像像素的分辨率高于文字中的文字。 为了解决这些差异, 我们提议了一个等级变换器, 其代表方式是用变换窗口来计算。 变换窗口方案通过将自我注意计算限制在不重叠的地方窗口中带来更大的效率, 同时也允许交叉窗口连接。 这种等级结构具有在不同尺度上建模的灵活性, 并在图像大小方面具有线性计算的复杂性。 Swin变换器的这些特性使得它与广泛的视觉任务相容异, 包括图像分类( 图像Net-1 的864 顶级精度), 以及物体检测( COCOCO 测试- develop) 和 语系分割( ADE20K val ) (3.5 mIU ) 。 它的性能表现超过先前的CO-art 模型, 由一个大型的 ASloudal/O- deliveK2 mess 和 OS AS.