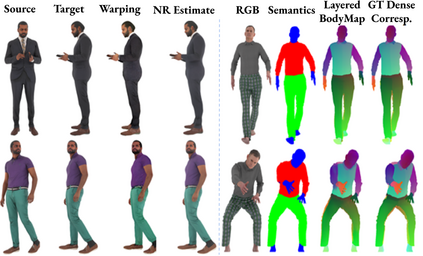
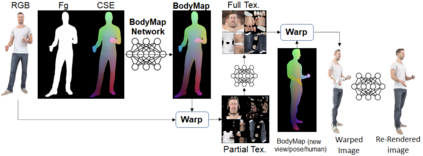
Dense correspondence between humans carries powerful semantic information that can be utilized to solve fundamental problems for full-body understanding such as in-the-wild surface matching, tracking and reconstruction. In this paper we present BodyMap, a new framework for obtaining high-definition full-body and continuous dense correspondence between in-the-wild images of clothed humans and the surface of a 3D template model. The correspondences cover fine details such as hands and hair, while capturing regions far from the body surface, such as loose clothing. Prior methods for estimating such dense surface correspondence i) cut a 3D body into parts which are unwrapped to a 2D UV space, producing discontinuities along part seams, or ii) use a single surface for representing the whole body, but none handled body details. Here, we introduce a novel network architecture with Vision Transformers that learn fine-level features on a continuous body surface. BodyMap outperforms prior work on various metrics and datasets, including DensePose-COCO by a large margin. Furthermore, we show various applications ranging from multi-layer dense cloth correspondence, neural rendering with novel-view synthesis and appearance swapping.
翻译:人与人之间的频繁对应含有强大的语义信息,可以用来解决全体理解的根本问题,例如圆形表面的匹配、跟踪和重建。在本文中,我们介绍“身体地图”,这是一个获得高清晰全体和连续密集的衣着人与3D模板模型表面之间连续密集对应的新框架。函文包括手和头发等细微细节,同时捕捉远离身体表面的区域,如衣物松散。先前用来估计这种密集的表面通信的方法i)将3D体切成未包装到2DUV空间的部分,产生部分接缝的不连续性,或(ii)使用单一表面来代表整个身体,但没有处理身体细节。这里,我们引入了带有视野变异器的新网络结构,在连续的身体表面学习精细的特征。机体图比先前关于各种测量和数据集的工作,包括大边缘的DensePose-CO。此外,我们展示了多种应用,包括多层密集面面面面面面面面面面的合成和新面合成。