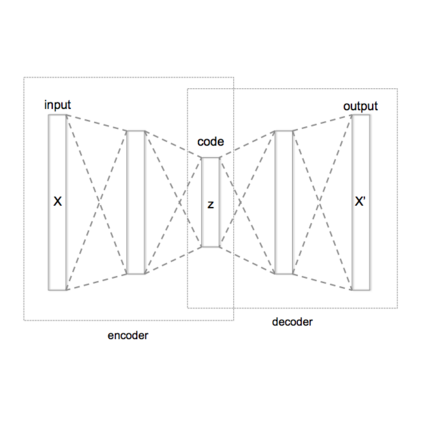
Predicting future frames of video sequences is challenging due to the complex and stochastic nature of the problem. Video prediction methods based on variational auto-encoders (VAEs) have been a great success, but they require the training data to contain multiple possible futures for an observed video sequence. This is hard to be fulfilled when videos are captured in the wild where any given observation only has a determinate future. As a result, training a vanilla VAE model with these videos inevitably causes posterior collapse. To alleviate this problem, we propose a novel VAE structure, dabbed VAE-in-VAE or VAE$^2$. The key idea is to explicitly introduce stochasticity into the VAE. We treat part of the observed video sequence as a random transition state that bridges its past and future, and maximize the likelihood of a Markov Chain over the video sequence under all possible transition states. A tractable lower bound is proposed for this intractable objective function and an end-to-end optimization algorithm is designed accordingly. VAE$^2$ can mitigate the posterior collapse problem to a large extent, as it breaks the direct dependence between future and observation and does not directly regress the determinate future provided by the training data. We carry out experiments on a large-scale dataset called Cityscapes, which contains videos collected from a number of urban cities. Results show that VAE$^2$ is capable of predicting diverse futures and is more resistant to posterior collapse than the other state-of-the-art VAE-based approaches. We believe that VAE$^2$ is also applicable to other stochastic sequence prediction problems where training data are lack of stochasticity.
翻译:预测视频序列的未来框架具有挑战性,因为问题的复杂性和随机性。基于变异自动摄像师(VAE)的视频预测方法非常成功,但是它们需要培训数据以包含观察到的视频序列的多种未来。当视频在野外拍摄时,任何特定观测都只能确定未来时,这很难实现。因此,用这些视频培训一个香草 VAE 模型不可避免地会导致后继崩溃。为了缓解这一问题,我们提议了一个新的 VAE 结构, 以变异性自动摄像师(VAE-in-VAE) 或 VAE2 A$2$2。关键的想法是明确将随机性数据包含在 VAE 中。我们把所观察到的视频序列中的部分视为随机性过渡状态,在任何特定的观察中,在任何可能的变异性视频序列中,马可最大限度地增加马尔多链在视频序列中的可能性。因此,为这一难解目标功能和端至端至端优化算法,因此,我们提出了一个新的VA$ $ 应用的VA- $ $ 或VA2$ (VA2$) e- liest A2$ (VA) (VA) (VA) (VA) (VA) (VA) (VA) (VA) (VA) (VA) (VA) (VA) ( VA) (V) ( VA) ( VA) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (V) (