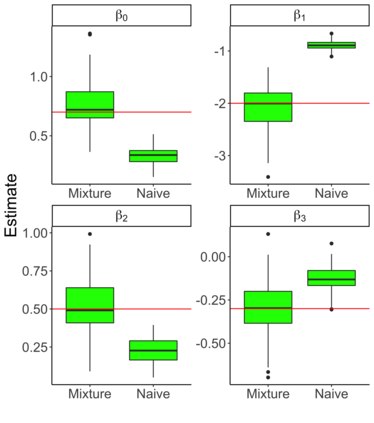
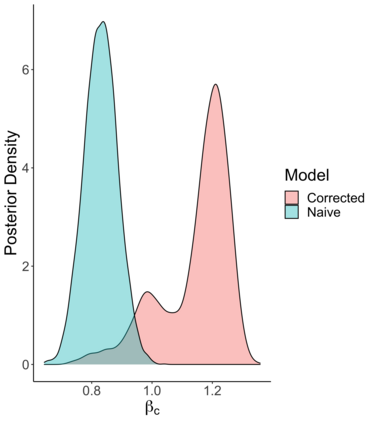
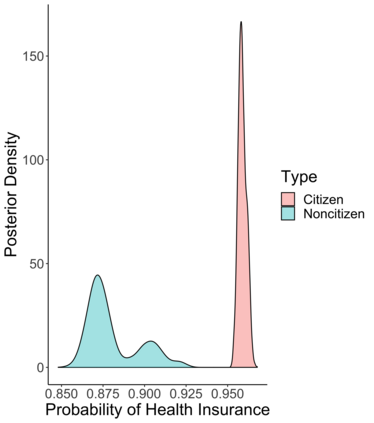
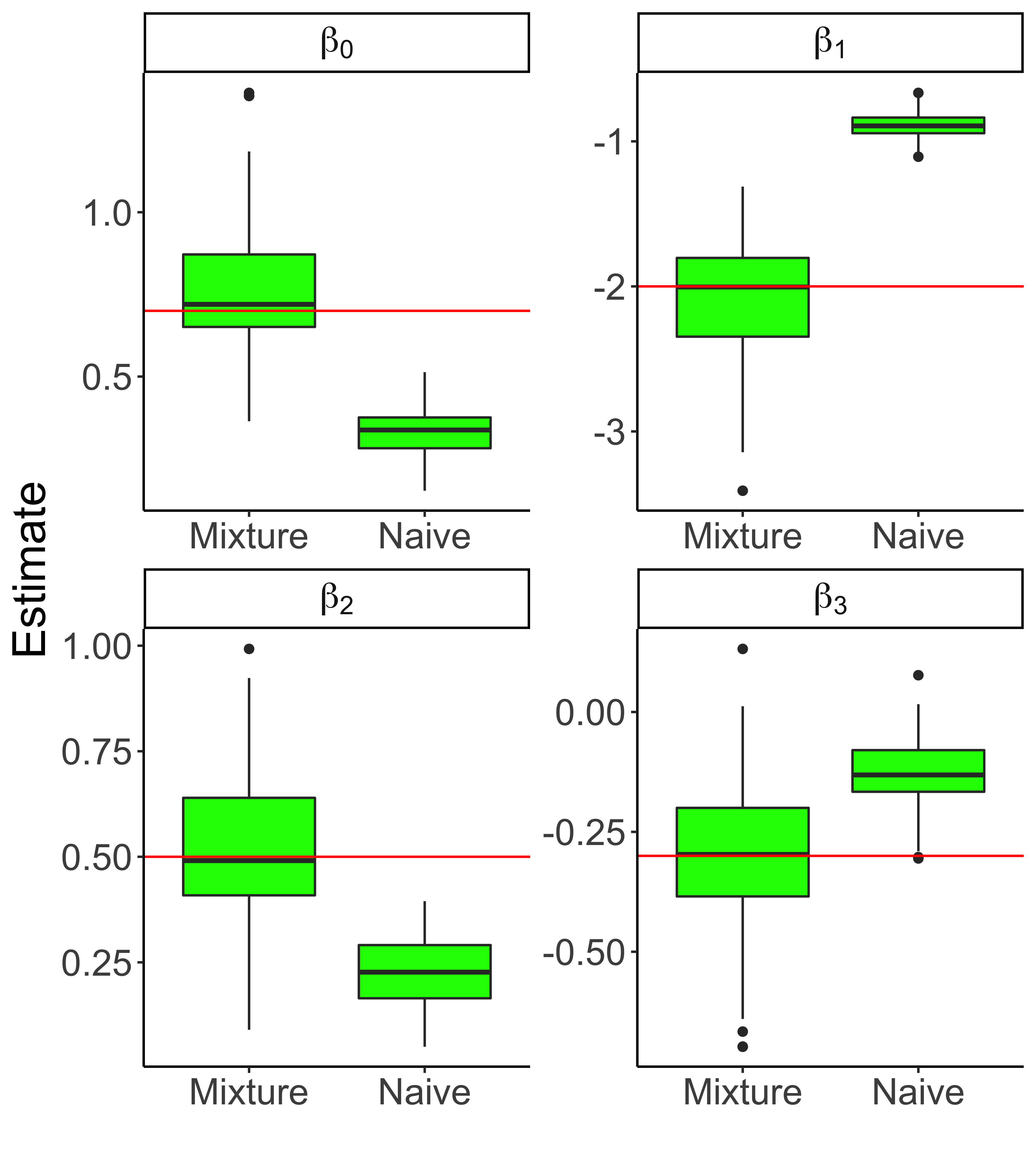
Social scientists are interested in studying the impact that citizenship status has on health insurance coverage among immigrants in the United States. This can be done using data from the Survey of Income and Program Participation (SIPP); however, two primary challenges emerge. First, statistical models must account for the survey design in some fashion to reduce the risk of bias due to informative sampling. Second, it has been observed that survey respondents misreport citizenship status at nontrivial rates. This too can induce bias within a statistical model. Thus, we propose the use of a weighted pseudo-likelihood mixture of categorical distributions, where the mixture component is determined by the latent true response variable, in order to model the misreported data. We illustrate through an empirical simulation study that this approach can mitigate the two sources of bias attributable to the sample design and misreporting. Importantly, our misreporting model can be further used as a component in a deeper hierarchical model. With this in mind, we conduct an analysis of the relationship between health insurance coverage and citizenship status using data from the SIPP.
翻译:暂无翻译