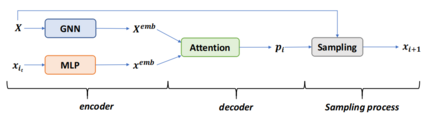
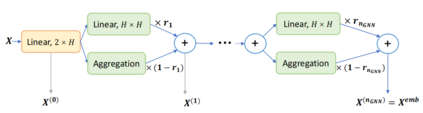
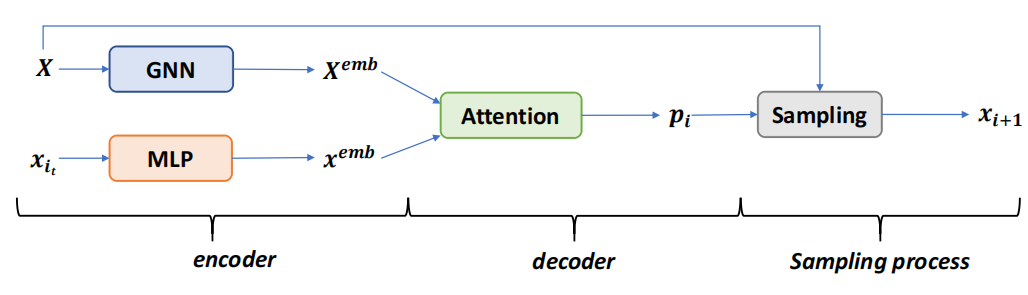
Recent work applying deep reinforcement learning (DRL) to solve traveling salesman problems (TSP) has shown that DRL-based solvers can be fast and competitive with TSP heuristics for small instances, but do not generalize well to larger instances. In this work, we propose a novel approach named MAGIC that includes a deep learning architecture and a DRL training method. Our architecture, which integrates a multilayer perceptron, a graph neural network, and an attention model, defines a stochastic policy that sequentially generates a TSP solution. Our training method includes several innovations: (1) we interleave DRL policy gradient updates with local search (using a new local search technique), (2) we use a novel simple baseline, and (3) we apply curriculum learning. Finally, we empirically demonstrate that MAGIC is superior to other DRL-based methods on random TSP instances, both in terms of performance and generalizability. Moreover, our method compares favorably against TSP heuristics and other state-of-the-art approach in terms of performance and computational time.
翻译:最近运用深入强化学习(DRL)解决旅行推销员问题的工作表明,基于DRL的解决方案可以对小型案例采用快速且具有竞争力的TSP喜剧性能,但不能对大案例加以概括。在这项工作中,我们提出了名为MAGIC的新方法,其中包括一个深层次学习架构和一个DRL培训方法。我们的架构将多层透视器、一个图形神经网络和一个关注模型结合起来,它定义了一种按顺序产生TSP解决方案的随机分析政策。我们的培训方法包括若干创新:(1) 我们用本地搜索(使用新的本地搜索技术)对DRL政策梯度进行互连更新,(2) 我们使用新的简单基线,(3) 我们应用课程学习。最后,我们从经验上证明,从性能和一般可操作性来看,MAGIC优于其他基于DL的随机TSP情况方法。此外,我们的方法与TSP的超常性能和计算时间方面其他最先进的方法相比是优的。