春节充电系列:李宏毅2017机器学习课程学习笔记31之深度强化学习(deep reinforcement learning)
【导读】我们在上一节的内容中已经为大家介绍了台大李宏毅老师的机器学习课程的ensemble。这一节将主要针对讨论deep reinforcement learning进行讨论。本文内容主要针对机器学习中deep reinforcement learning的增强学习的概念、Policy-based Approach以及公式推导进行详细介绍,话不多说,让我们一起学习这些内容吧。
春节充电系列:李宏毅2017机器学习课程学习笔记25之结构化学习-序列标注 Sequence Labeling(part 1)
春节充电系列:李宏毅2017机器学习课程学习笔记26之结构化学习-序列标注 Sequence Labeling(part 2)
春节充电系列:李宏毅2017机器学习课程学习笔记27之循环神经网络 Recurrent Neural Network
春节充电系列:李宏毅2017机器学习课程学习笔记28之循环神经网络 Recurrent Neural Network Part2
春节充电系列:李宏毅2017机器学习课程学习笔记29之循环神经网络 Recurrent Neural Network Part3
春节充电系列:李宏毅2017机器学习课程学习笔记30之集成学习 (Ensemble Learning)
课件网址:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17.html
视频网址:
https://www.bilibili.com/video/av15889450/index_1.html
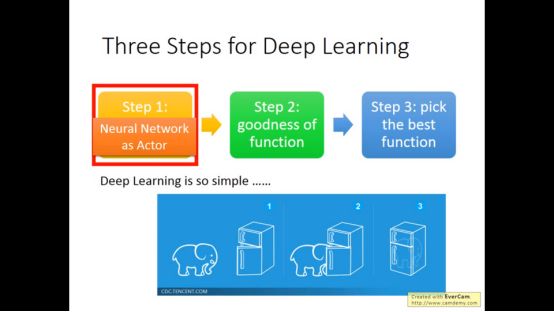
李宏毅机器学习笔记31 深度强化学习(deep reinforcement learning)
▌1.增强学习的概念
增强学习有两个重要部分,一个是agent,一个是environment。

Agent从环境中观察环境的状态
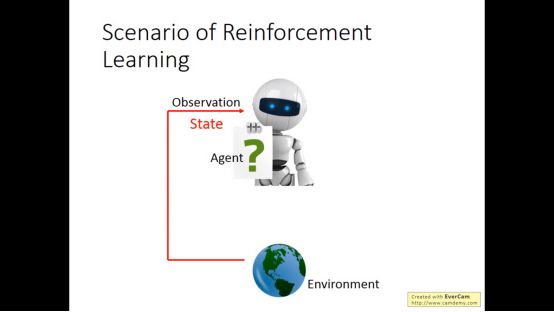
然后agent根据看到的状态采取行动,进而改变
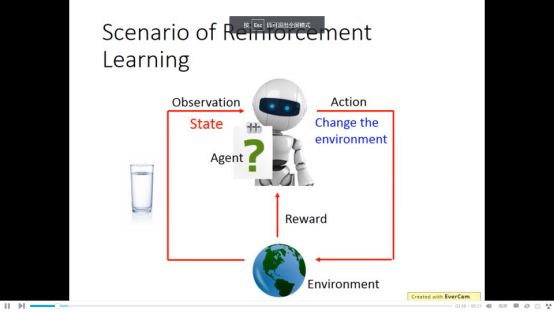
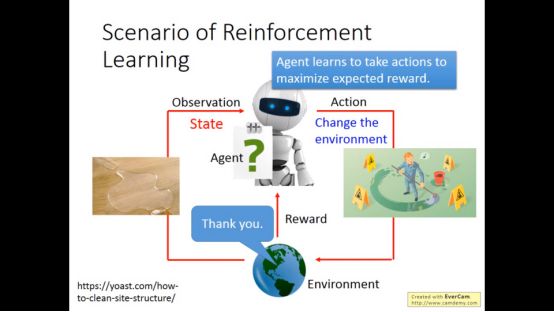
然后agent会得到一个reward,agent每次采取的行动都尽量使得reward最大
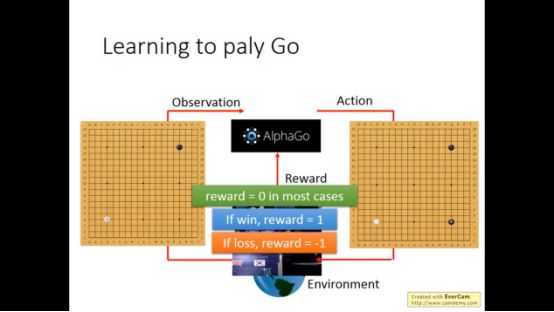
比如对于下围棋来说,赢了reward是1,输了reward是0
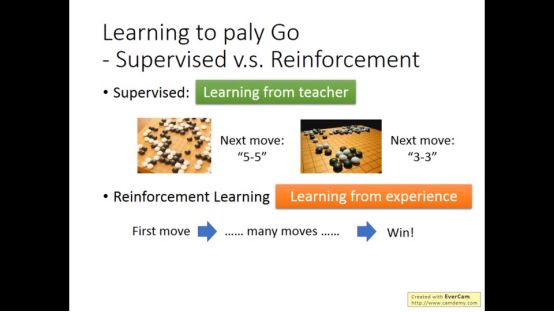
简单来说,监督学习机器是从老师那里学习,而增强学习则是从经验那里学习的
增强学习也可以用来训练chat-bot

当然还有更多的应用

在打电脑游戏中可以用到增强学习
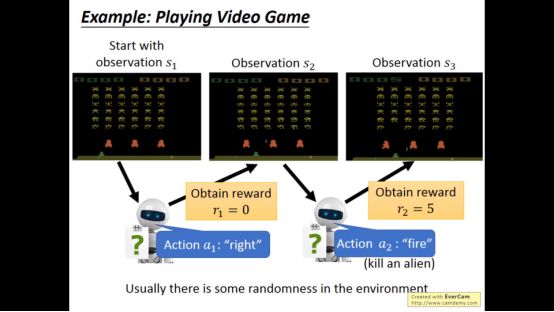
增强学习困难在于reward可能不是立马就会得到,比如在下围棋时可能需要短暂的牺牲以便在以后获得更大的优势

增强学习主要分为两大类,一个是policy-based,另一个是value-based
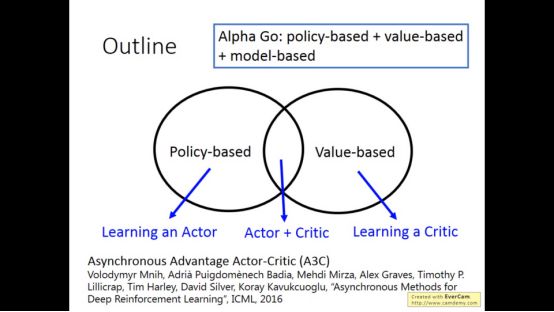
▌2. Policy-based Approach
今天主要讲述policy-based approach

Action是要根据目前看到的状态采取行动
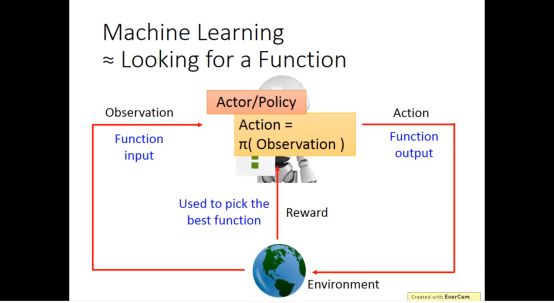
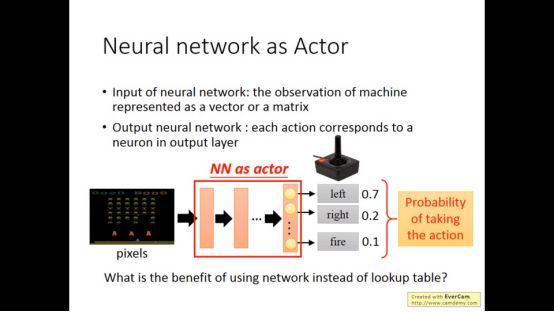
当actor是neural network是,增强学习就变成深度增强学习了
根据目前的状态NN输出要采取行动的概率
Reward我们最后取的是total reward

我们需要取total reward的期望,因为即使在不同的实验中我们采取同样的actor,我们得到的reward依然是不一样的

▌3.公式推导
于是增强学习的问题可以归结如下

继续化简

对于P(τ|θ)我们可以得到
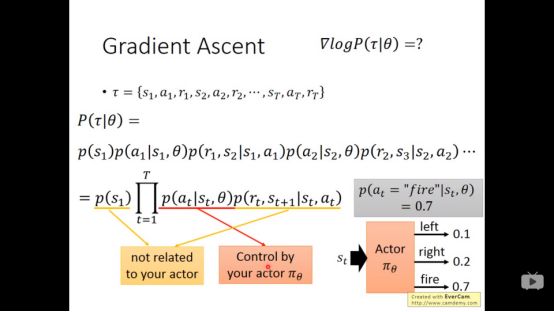
忽视与θ无关的项

带入式子中我们可以得到
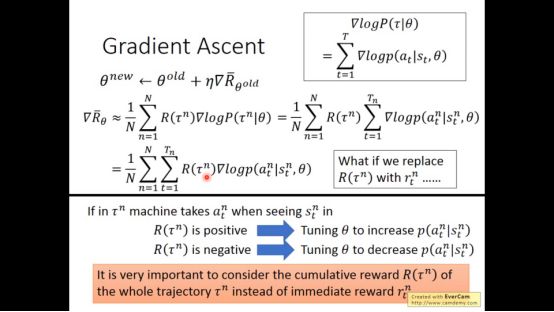
当然这还不够,现实和梦想总有差距的,而且差距很大。
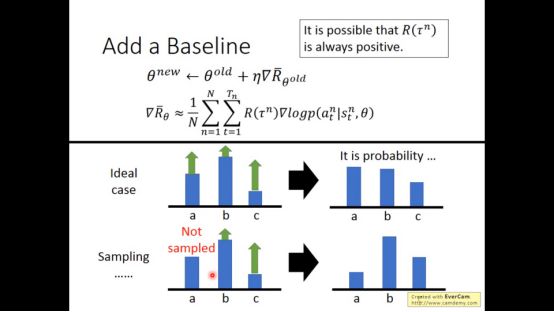
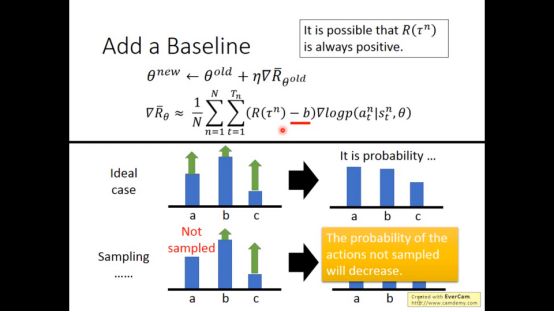
我们需要增加一个baseline,当大于baseline的值几率增加,小于baseline的值几率减小。可以很好的减轻以上情况
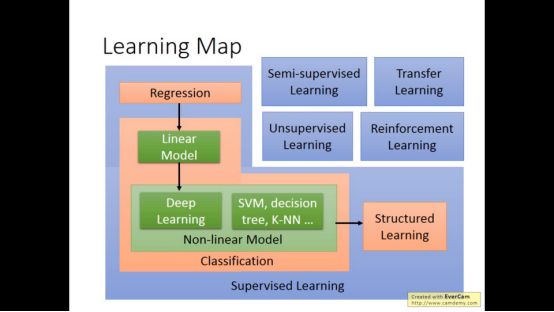
到此为止,课程全部结束了,我们总共讲述了以上部分,当然这些内容并不是机器学习的全部内容,仅仅是机器学习的简单入门,在学习过程中也验证了数学的重要性。年轻人不要心浮气躁,地基打牢固了才能建成摩天大楼。
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“LHY2017” 就可以获取 2017年李宏毅中文机器学习课程下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

点击“阅读原文”,使用专知!



