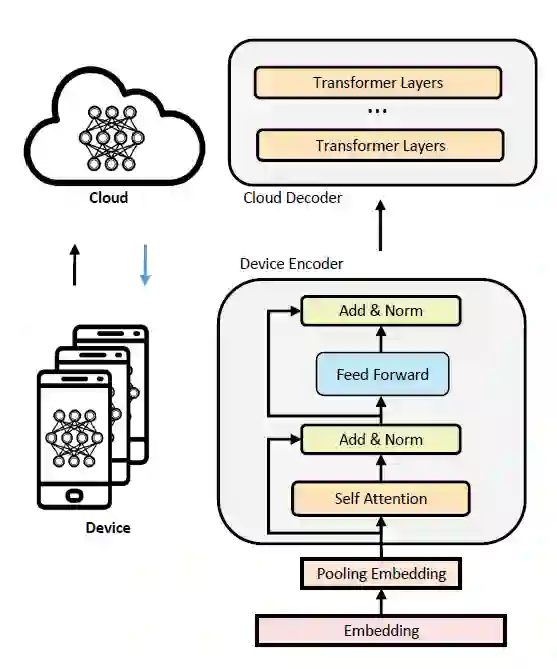
Unsupervised pre-training approaches have achieved great success in many fields such as Computer Vision (CV), Natural Language Processing (NLP) and so on. However, compared to typical deep learning models, pre-training or even fine-tuning the state-of-the-art self-attention models is extremely expensive, as they require much more computational and memory resources. It severely limits their applications and success in a variety of domains, especially for multi-task learning. To improve the efficiency, we propose Device Tuning for the efficient multi-task model, which is a massively multitask framework across the cloud and device and is designed to encourage learning of representations that generalize better to many different tasks. Specifically, we design Device Tuning architecture of a multi-task model that benefits both cloud modelling and device modelling, which reduces the communication between device and cloud by representation compression. Experimental results demonstrate the effectiveness of our proposed method.
翻译:未经监督的培训前方法在许多领域取得了巨大成功,如计算机视野(CV)、自然语言处理(NLP)等。然而,与典型的深层学习模式相比,培训前甚至微调最先进的自我关注模式非常昂贵,因为它们需要更多的计算和记忆资源。它严重限制了它们在多个领域的应用和成功,特别是在多任务学习方面。为了提高效率,我们提议为高效的多任务模式提供设备测试,该模式是云层和装置之间的一个庞大的多任务框架,旨在鼓励学习能够更好地概括许多不同任务的表达方式。具体地说,我们设计多任务模式的设备图案结构,既有利于云建模,也有利于设备建模,通过压缩表达方式减少设备与云的沟通。实验结果显示了我们拟议方法的有效性。