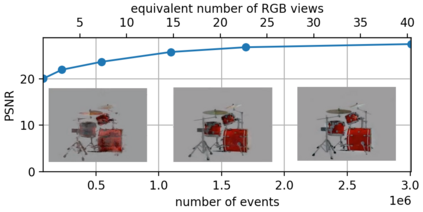
Learning coordinate-based volumetric 3D scene representations such as neural radiance fields (NeRF) has been so far studied assuming RGB or RGB-D images as inputs. At the same time, it is known from the neuroscience literature that human visual system (HVS) is tailored to process asynchronous brightness changes rather than synchronous RGB images, in order to build and continuously update mental 3D representations of the surroundings for navigation and survival. Visual sensors that were inspired by HVS principles are event cameras. Thus, events are sparse and asynchronous per-pixel brightness (or colour channel) change signals. In contrast to existing works on neural 3D scene representation learning, this paper approaches the problem from a new perspective. We demonstrate that it is possible to learn NeRF suitable for novel-view synthesis in the RGB space from asynchronous event streams. Our models achieve high visual accuracy of the rendered novel views of challenging scenes in the RGB space, even though they are trained with substantially fewer data (i.e., event streams from a single event camera moving around the object) and more efficiently (due to the inherent sparsity of event streams) than the existing NeRF models trained with RGB images. We will release our datasets and the source code, see https://4dqv.mpi-inf.mpg.de/EventNeRF/.
翻译:根据神经科学文献,人们从神经科学文献中知道,人类视觉系统(HVS)是针对非同步光亮变化而设计的,而不是同步的 RGB 图像,目的是从无同步事件流中建立和不断更新周围的智能3D表现,以导航和生存为目的。受HVS原则启发的视觉传感器是事件相机。因此,事件很少,而且无同步的每像亮度(或彩色频道)变化信号。与现有的神经3D场展示学习工作相比,本文从新角度处理问题。我们证明,有可能从无同步事件流中学习适合RGB空间新视觉合成的NERF。我们的模型在 RGBpi 空间挑战性场景的新观点中实现了高视觉精确度,尽管它们经过了大量的数据培训(即单个事件相机流流,在物体周围移动,RRF4 和我们所训练的RFRF 的内流数据流)和我们所训练的RFRF 的内生数据流(由于我们所了解的源/内生的RFRF ) 。