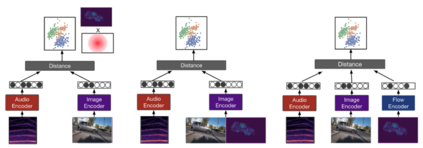
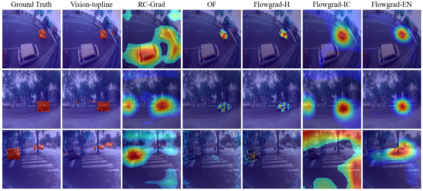
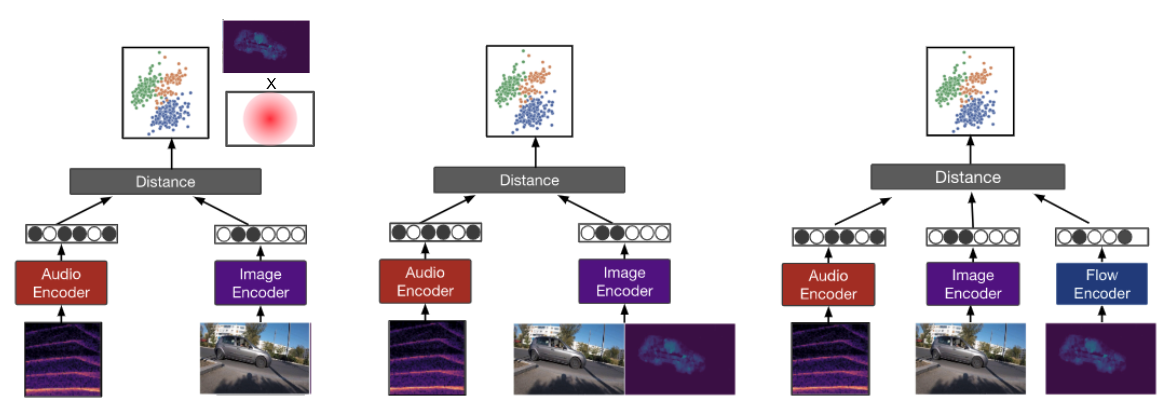
Most recent work in visual sound source localization relies on semantic audio-visual representations learned in a self-supervised manner, and by design excludes temporal information present in videos. While it proves to be effective for widely used benchmark datasets, the method falls short for challenging scenarios like urban traffic. This work introduces temporal context into the state-of-the-art methods for sound source localization in urban scenes using optical flow as a means to encode motion information. An analysis of the strengths and weaknesses of our methods helps us better understand the problem of visual sound source localization and sheds light on open challenges for audio-visual scene understanding.
翻译:视觉声源本地化的最新工作依赖于以自我监督的方式学习的语义视听表述,而设计时则排除了视频中存在的时间信息。虽然这种方法已证明对广泛使用的基准数据集有效,但对于城市交通等具有挑战性的情景来说却不尽如人意。这项工作将时间背景引入城市景区最先进的声源本地化方法中,利用光学流将运动信息编码。分析我们方法的优缺点有助于我们更好地了解视觉声源本地化问题,并揭示视听景区理解的公开挑战。