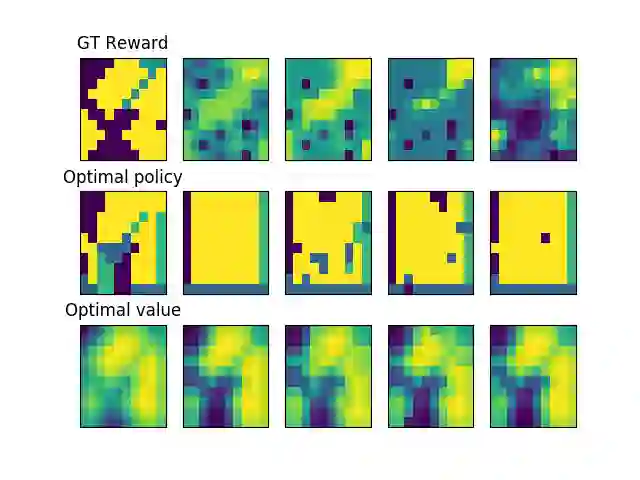
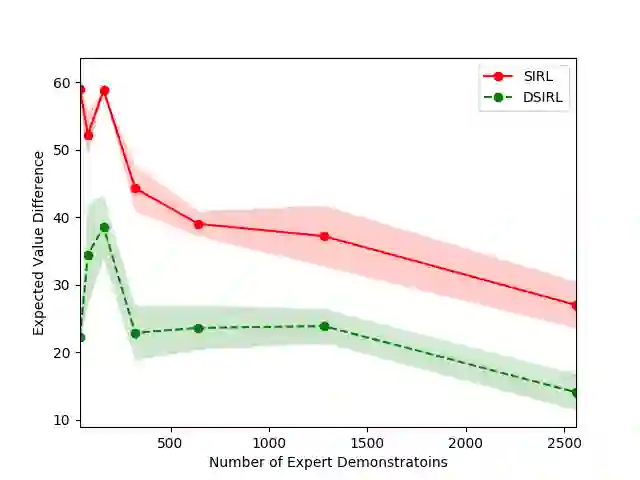
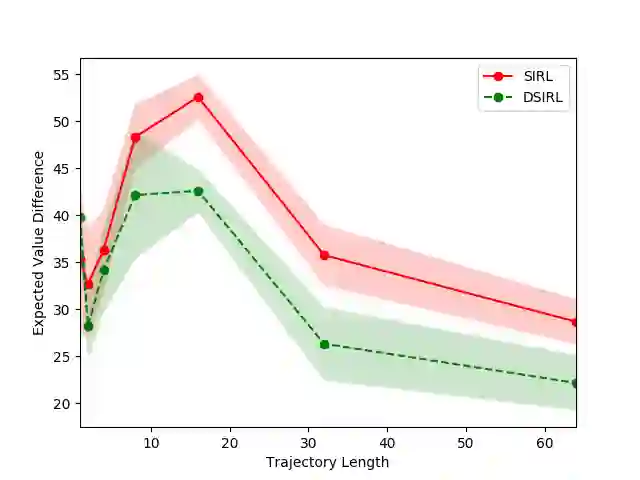
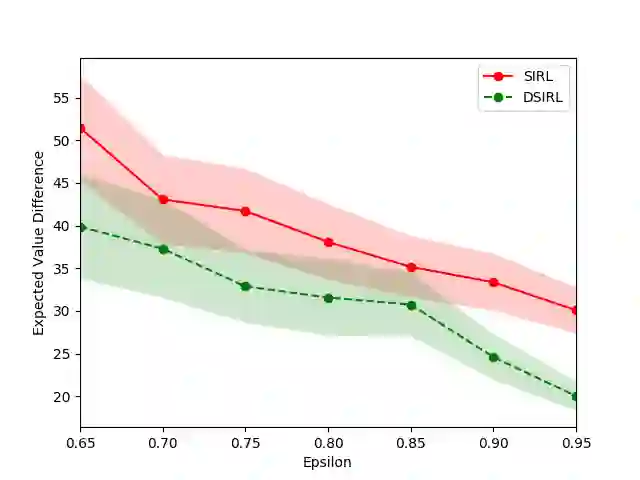
The goal of the inverse reinforcement learning (IRL) problem is to recover the reward functions from expert demonstrations. However, the IRL problem like any ill-posed inverse problem suffers the congenital defect that the policy may be optimal for many reward functions, and expert demonstrations may be optimal for many policies. In this work, we generalize the IRL problem to a well-posed expectation optimization problem stochastic inverse reinforcement learning (SIRL) to recover the probability distribution over reward functions. We adopt the Monte Carlo expectation-maximization (MCEM) method to estimate the parameter of the probability distribution as the first solution to the SIRL problem. The solution is succinct, robust, and transferable for a learning task and can generate alternative solutions to the IRL problem. Through our formulation, it is possible to observe the intrinsic property of the IRL problem from a global viewpoint, and our approach achieves a considerable performance on the objectworld.
翻译:反强化学习(IRL)问题的目标是从专家示范中恢复奖励功能。然而,IRL问题,如任何错误的反向问题,都存在先天缺陷,即该政策对于许多奖励职能而言可能是最佳的,专家示范可能对于许多政策来说是最佳的。在这项工作中,我们将IRL问题概括为预期最佳化问题,将预期最佳化问题归纳为预期最佳化问题,以恢复奖励职能的概率分配。我们采用了蒙特卡洛预期-最大化(MCEM)方法来估计概率分布参数,作为SIRL问题的第一个解决方案。解决方案简洁、有力,可以用于学习任务,并可以产生解决IRL问题的替代方案。通过我们的制定,我们有可能从全球角度观察IRL问题的内在特性,我们的方法在对象世界取得了相当大的表现。